







Сценарии обработки данных - База знаний Modus
Сценарии обработки данных — это инструмент для подготовки данных, полученных из учетных систем, к использованию в отчетах и аналитике. Они применяются на этапе, когда сырые данные необходимо преобразовать в удобный для анализа формат.
Подготовка данных включает выполнение различных операций на языках SQL, 1C или Python, таких как:
- Очистка данных от ошибок и дубликатов.
- Дополнение данных недостающей информацией.
- Агрегация и объединение данных из разных источников.
- Расчет ключевых показателей.
- Сервисные операции: выгрузка, загрузка, перемещение файлов и удаление архивных копий таблиц.
Для настройки этих операций используется документ «Сценарий обработки данных», где задаются и настраиваются шаги сценария.
Чтобы открыть список сценариев, перейдите в раздел «Сценарии обработки данных»:
- С начальной страницы.
- Или из меню: «Главная/ Настройки/ Сценарии».
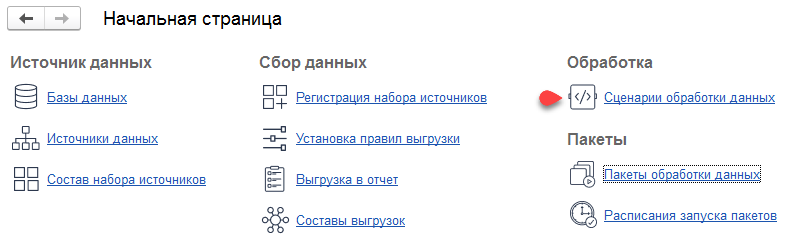
В списке сценариев вы можете:
- Создать новый сценарий.
- Отредактировать существующий сценарий.
- Запустить сценарий.

Кнопка ![]() позволяет запустить на выполнение шаги сценария (см. рисунок выше, 1).
позволяет запустить на выполнение шаги сценария (см. рисунок выше, 1).
Кнопка «Только примитивы» включает отбор служебных сценариев (примитивов) (см. рисунок выше, 2). Чтобы отключить отбор, нажмите на эту кнопку еще раз.
Настройка сценария обработки данных
Порядок настройки «Сценария обработки данных» следующий:
- На вкладке «Основное» заполните поля:
- «Наименование сценария».
- «База данных» (выбор из списка БД).
- «Тип» — заполняется автоматически как «Произвольная последовательность шагов». Другие типы используются для автоматически создаваемых сценариев обработки данных, таких как «Трансформация» или «Верификация данных».
- «Проект» — при необходимости укажите «Проект»
- «Комментарий» — текстовое поле при необходимости возможно заполнить дополнительной информацией по обработке данных.

- Настройте сценарий на вкладке «Шаги сценария». Напишите для каждого шага скрипт на языке SQL/1С или используйте для настройки и авто-генерации скрипта готовые шаблоны.
- На вкладке «Шаги сценария» по умолчанию включен интерфейс «WorkFlow».
Помимо основного процесса трансформации данных он позволяет дополнительно настроить:
- Сохранение информации для профилирования данных: сэмплы данных, статистику по значениям и качеству данных.
- Сохранение и просмотр логов работы.
-
Шаги сценария могут выполняться параллельно.
- Для изменения старых сценариев интерфейс «WorkFlow» может быть недоступен и система сообщит о несовместимости. В этом случае используйте для редактирования старый интерфейс, без использования «WorkFlow». Подробнее о настройке шагов смотрите в разделе «Шаги сценария (старый интерфейс)».

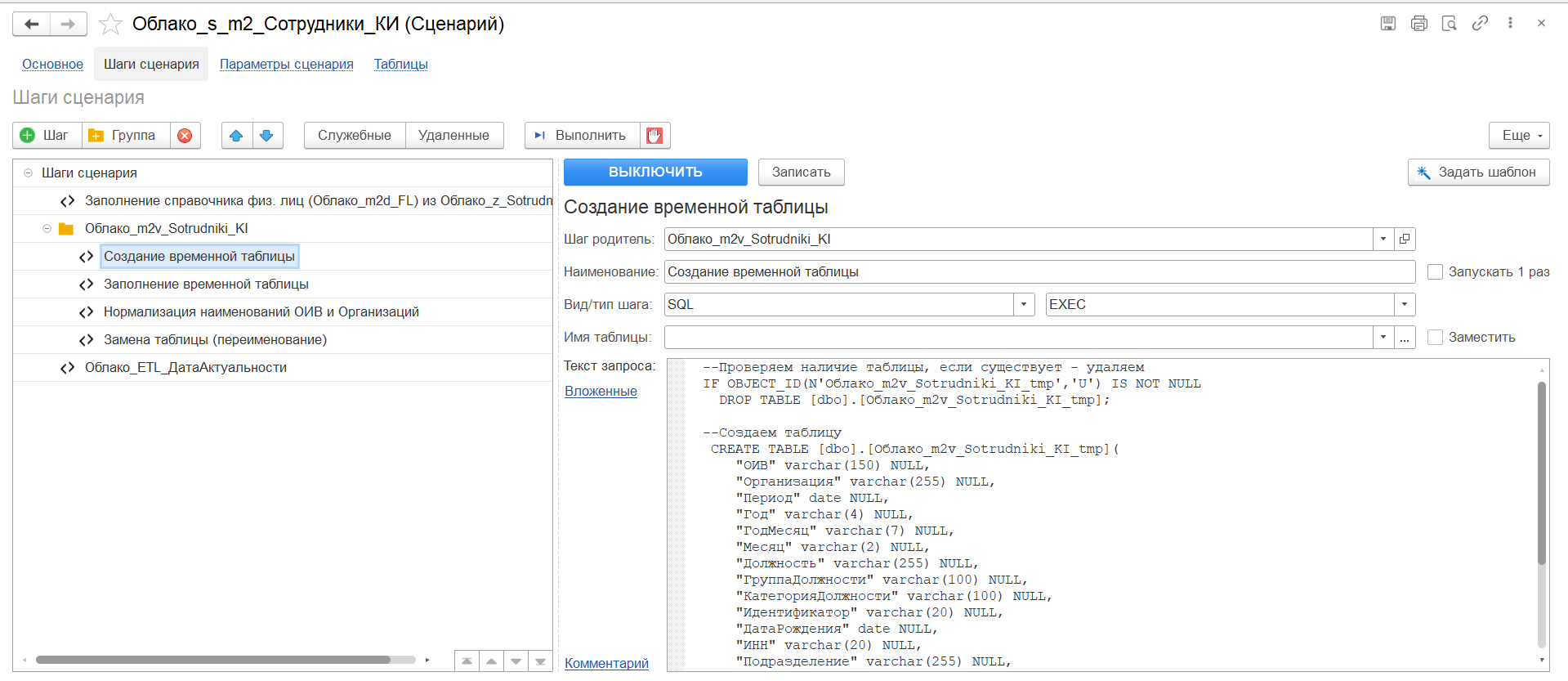
- На вкладке «Шаги сценария» по умолчанию включен интерфейс «WorkFlow».
- На вкладке «Параметры сценария» возможно ввести параметры, которые будут использоваться в настройках / тексте скриптов шагов. Вы можете не заполнять значения параметров, если предполагается запуск сценария только через «Пакеты обработки данных», подробнее смотрите в разделе «Настройка пакетов обработки данных».
- Нажмите на кнопку «Записать и закрыть» на вкладке «Основное», чтобы сохранить сценарий.
Вкладка «Таблицы»
В данной вкладке отображаются таблицы, созданные в сценарии.
Отображаются внутри данной вкладки еще 2 вкладки:
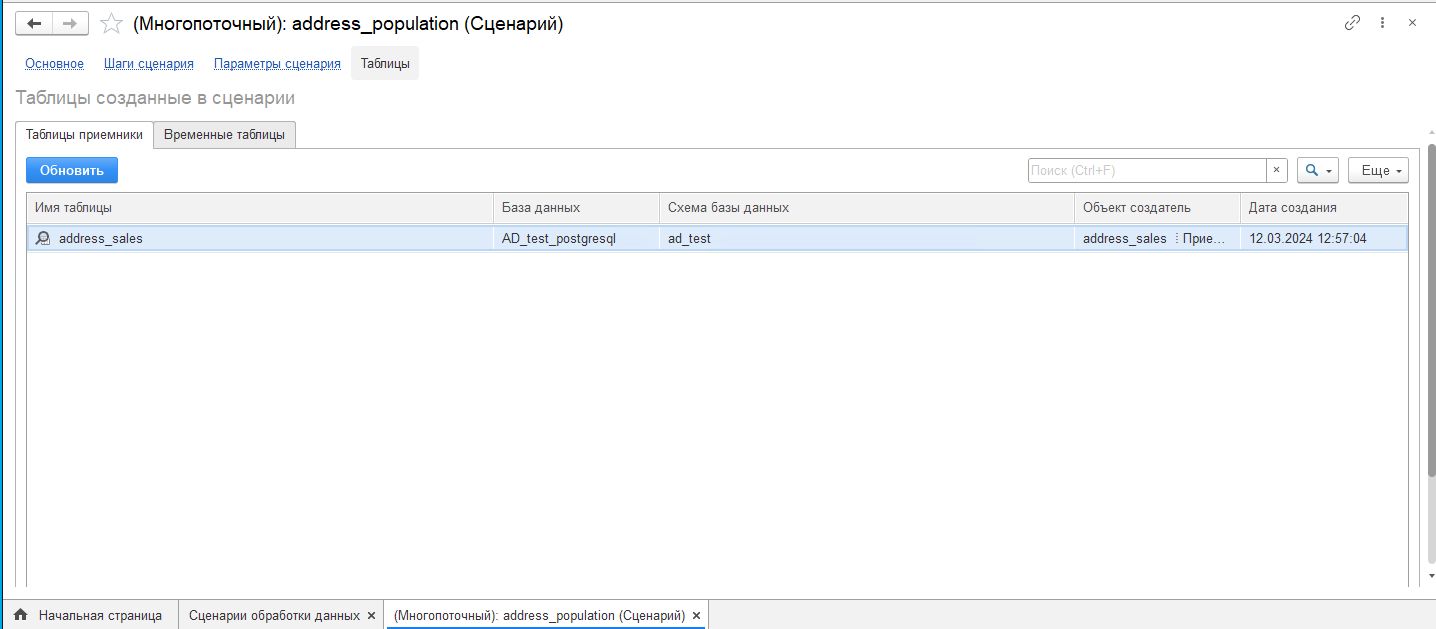
- «Таблицы приемники» — таблицы, которые создаются в сценарии на шаге «Приемник» отображаются на данной вкладке;
- «Временные таблицы» — если связь между шагами «Временная таблица» (а не «Вложенный запрос»), то они после запуска сценария отобразятся на данной вкладке.
На вкладке «Таблицы приемника» при нажатии на кнопку «Обновить» происходит обновление списка таблиц приемников. При отсутствии приемника в сценарии на вкладке записи не отображаются. При двойном нажатии по строке откроется просмотр таблицы.
На вкладке «Временные таблицы» при нажатии на кнопку «Обновить» происходит обновление списка таблиц до изменений, произведенных с момента создания страницы. До запуска сценария на вкладке не отображаются записи. При двойном нажатии по строке откроется просмотр таблицы.
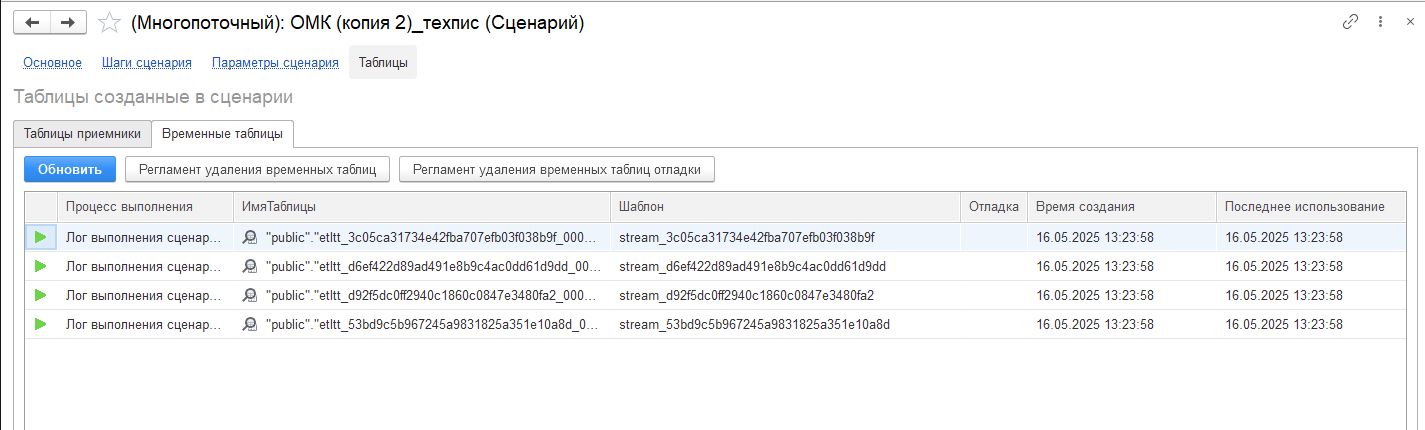
Примечание — работа с кнопками «Регламент удаления временных таблиц» и «Регламент удаления временных таблиц отладки» — это фоновые процессы, запускаемые по расписанию платформой 1С. Для пользователя процесс запуска и работы фоновых процессов не заметен. Данные кнопки решено было оставить на случай появления каких-либо проблем, чтобы наш специалист мог вручную запускать эти регламенты. Регламенты по удалению временных таблиц не имеют каких-либо UI внешних признаков своей работы.
Пояснение:
- Когда шаги сценария выполняются, ЕTL создает таблицы в хранилище для передачи данных между шагами. С точки зрения СУБД это обычные таблицы, не временные. Но для ЕTL они временные, т.к. ЕTL сам следит за тем чтобы их удалять, после того как они перестают быть нужными. В норме, если таблицы созданы при автоматическом выполнении сценария и удаляются сразу по окончании выполнения сценария. Но если сценарий был прерван, остановлен или произошла остановка сервера 1С, то таблицы будут удалены спустя какое-то время, специальным кодом. Код выполняется периодически — это и есть действие кнопки «Регламент удаления временных таблиц».
- Еще есть таблицы, создаваемые при отладочном (ручном) выполнении сценария или отдельных шагов. Эти таблицы тоже нужно удалить после того, как они больше не будут нужны — когда пользователь закроет форму элемента справочника «Сценарии». Удаляются они не сразу, а периодически - это и есть действие кнопки «Регламент удаления временных таблиц отладки».