







Шаблоны примитивов обработки данных - База знаний Modus
Данная группа автоматизирует базовые операции по трансформации, агрегации, очистке данных и дополнительным расчетам.
Произвольная выборка
Шаблон «Произвольная выборка» — эффективный инструмент для выборки, очистки, трансформации данных и вспомогательных расчетов. Шаг настраивается в окне «Мастер настройки выборки данных». По умолчанию активна вкладка «Настройка полей запроса».
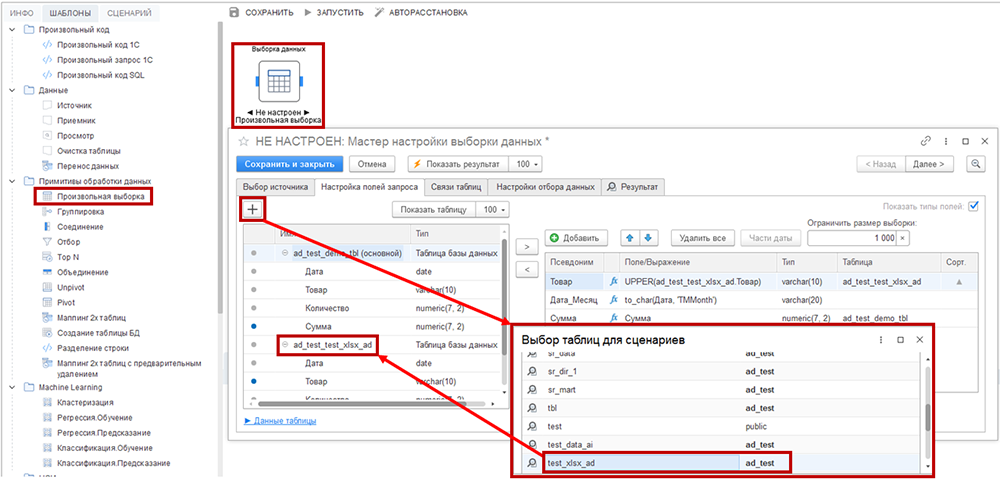
Как в большинстве шаблонов группы, вкладка имеет два секции: левую (источники данных) и правую (поля новой таблицы, которую создаёт шаг сценария).
Сначала задается один обязательный источник данных, который отображается на первой вкладке «Выбор источника». Если шаг сценария связан с предыдущим, то источником будет таблица, созданная на предыдущем шаге (например, с помощью шаблона «Источник» или других примитивов обработки данных).
Для создания новой таблицы возможно выбирать и преобразовывать поля из нескольких таблиц. Для этого нажмите на кнопку со знаком «+» и выберите дополнительную таблицу-источник в диалоговом окне «Выбор таблиц для сценариев». Новая таблица появится в левой части интерфейса. Удалить таблицу-источник можно через контекстное меню, которое вызывается правой кнопкой мыши.
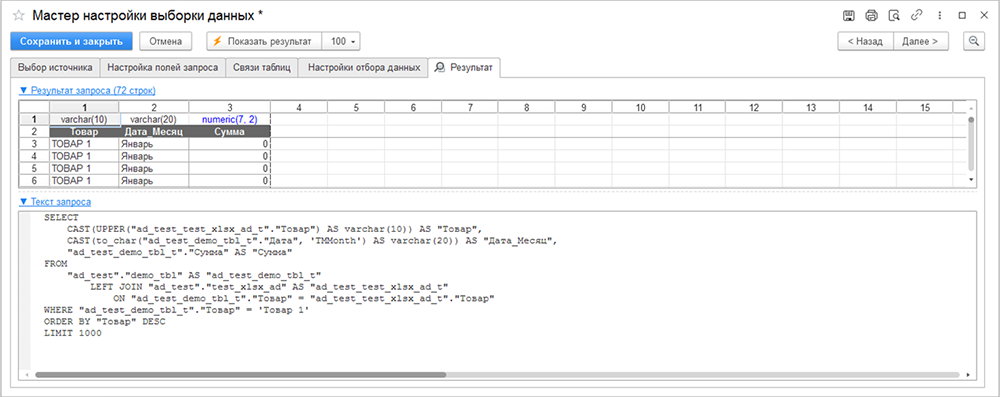
Нужные для выборки поля перемещаются из левой секции в правую с помощью мыши (методом drag-and-drop), или кнопок «>» и «<». На предыдущем рисунке использованы поля «Товар» (из таблицы «test_xlsx_ad») и «Сумма» (из таблицы «demo_tbl»), а на основе поля «Дата» (из таблицы «demo_tbl») сгенерировано новое поле «Дата_Месяц». Точка напротив использованных полей в исходной таблице меняет цвет на синий.
В правой секции вкладки «Настройка полей запроса» вы можете:
- добавлять, удалять поля новой таблицы. Предусмотрены кнопки «Добавить» и «Удалить все»;
- менять порядок полей сверху вниз (кнопками со стрелками над секцией). Это влияет на порядок полей слева направо (соответственно) формируемой таблицы;
- задавать псевдоним нового поля ручным вводом в колонке «Псевдоним» (по умолчанию имена полей совпадают с исходными, либо генерируются автоматически при создании части даты);
- трансформировать выражения, производить дополнительные расчеты с помощью вставок кода на SQL. Для этого в колонке «Поле/Выражение» дважды щелкните мышью, появится кнопка с символом троеточия «…». Нажмите на нее и в открывшейся форме «Произвольное выражение» (рисунок ниже) вручную введите код;
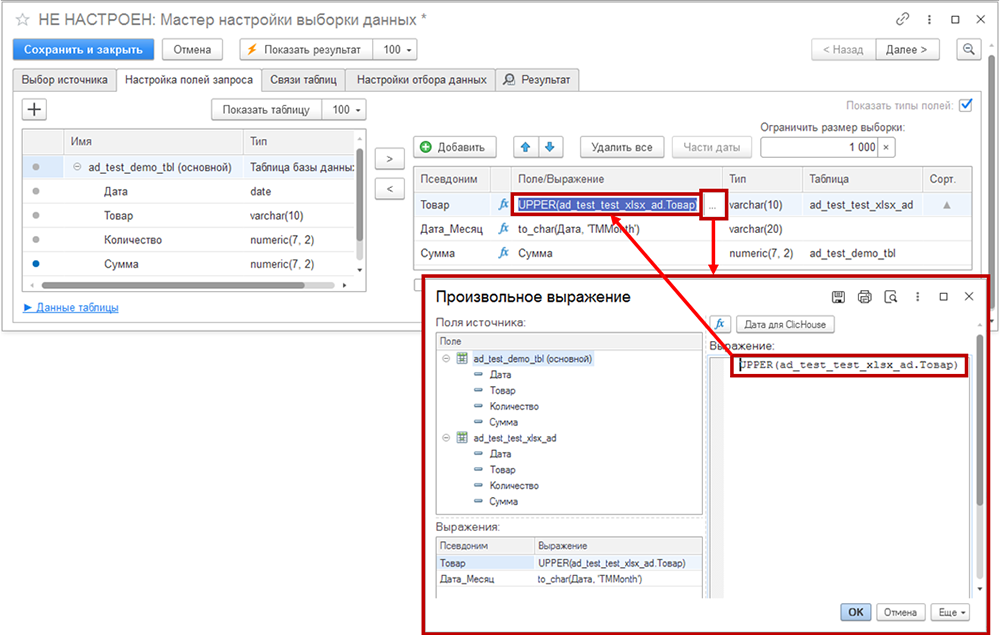
- менять тип полей в новой таблице с помощью колонки «Тип». Интерфейс аналогичный колонке «Поле/Выражение» — двойной щелчок мыши и кнопка «…»;
- задавать сортировку по полю. Двойной щелчок мыши в колонке «Сорт.» задает сортировку по убыванию, возрастанию (поле «Товар»), либо удаляет сортировку. Сортировка работает, если в поле «Ограничить размер выборки» введено число строк. При включенной сортировке появляется символ треугольника.
Селектор «Выбирать различные данные» в нижней части вкладки позволяет извлекать только уникальный список значений (без повторов).
Возможно использовать поле с датой и временем в трансформированном виде (извлечь месяц, год и т.д.). Для этого добавьте поле в правую секцию, выделите его и нажмите на кнопку «Части даты». Появится окно с различными вариантами для выбора. После добавления трансформированного результата вы можете удалить исходное поле с датой, и оставить только преобразованный вариант даты.
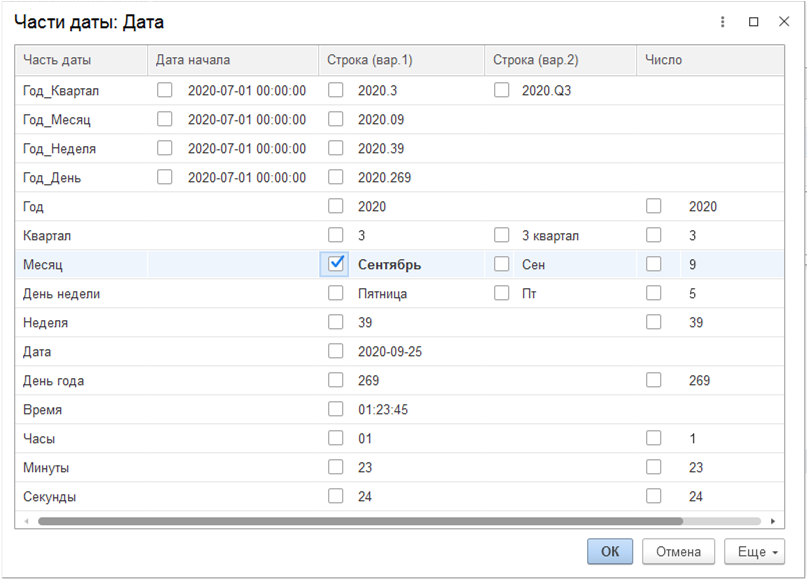
В примере из поля «Дата» извлечено название месяца на русском языке. После закрытия окна в столбце «Поле/Выражение» генерируется код на SQL:
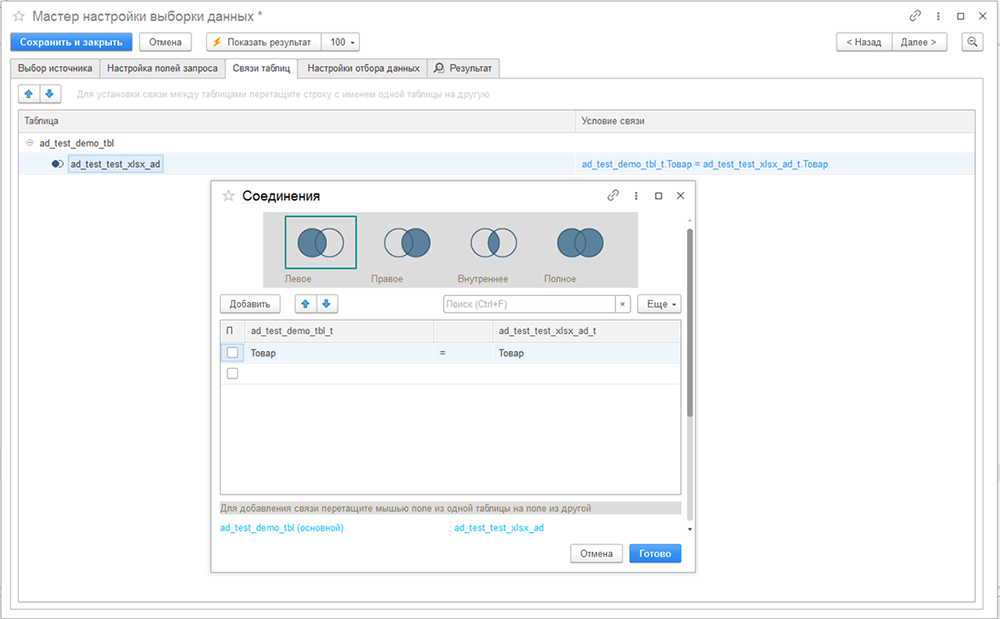
Если в шаге данные собираются из нескольких таблиц, свяжите исходные таблицы между собой (вкладка «Связи таблиц»). Двойной щелчок мыши по названию нижестоящей таблицы «test_xlsx_ad» вызывает диалоговое окно «Соединения». В открывшемся окне выберите тип соединения («Левое») и связанные поля («Товар»).
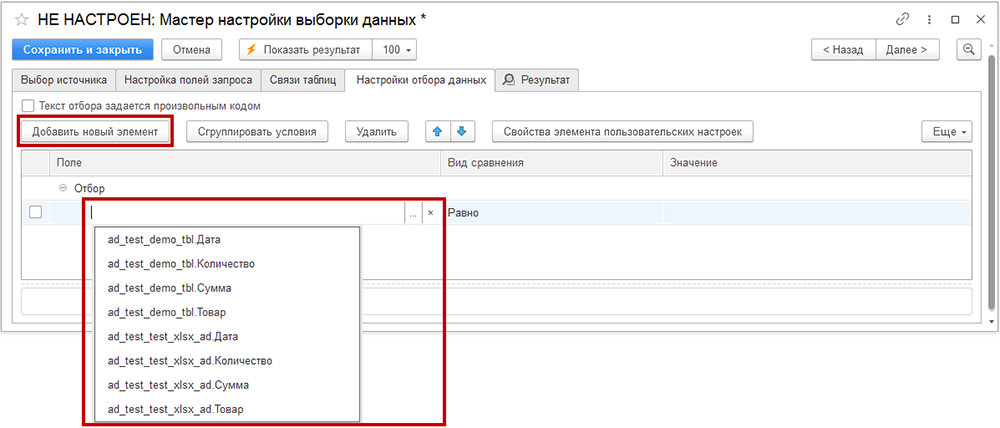
При необходимости возможно настроить фильтрацию данных в исходных таблицах по заданным условиям. Для этого перейдите на вкладку «Настройка отбора данных».
Как настроить отбор:
- Нажмите на кнопку «Добавить новый элемент» (справа также доступны кнопки для группировки условий и удаления).
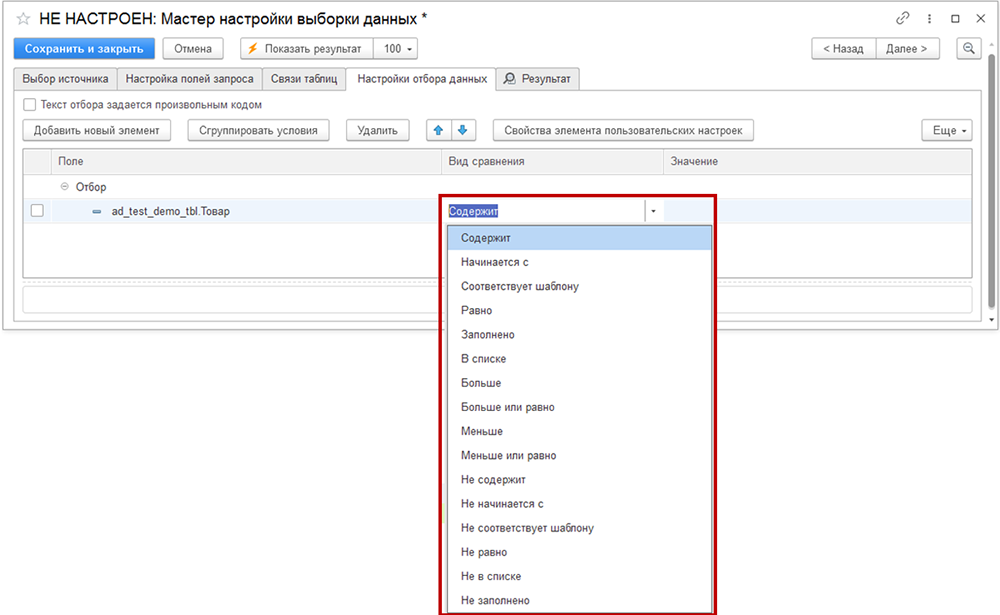
- Укажите поле для отбора, выберите вид сравнения и введите значение в колонке «Значение».
Возможно задать сразу несколько отборов для более точной фильтрации данных.
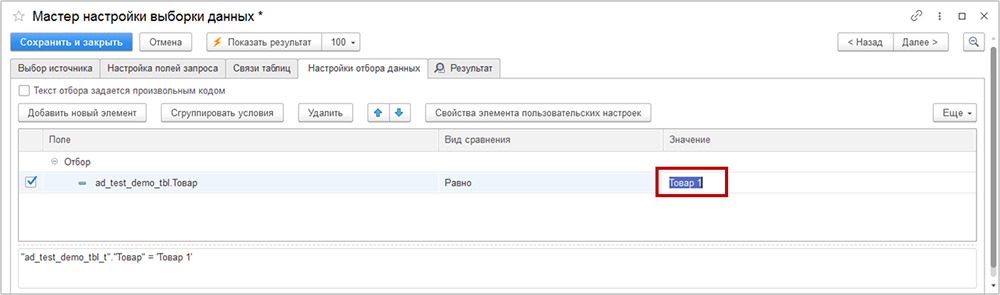
В итоге, в нижней части окна появится SQL-код условий отбора:
Для настройки сложных условий фильтрации возможно использовать группировку условий:
- логическое «И» — все условия в группе должны выполняться одновременно;
- логическое «НЕ» — ни одно из условий в группе не должно выполняться;
- логическое «ИЛИ» — достаточно выполнения хотя бы одного условия из группы.
Как настроить группировку:
- Выделите несколько условий.
- Нажмите на кнопку «Сгруппировать условия».
- Выберите нужный логический вариант в заголовке группы.
Также возможно вручную ввести SQL-код отбора, активировав режим «Текст отбора задается произвольным кодом».
На вкладке «Результат» вы можете:
- посмотреть, какая таблица получится на выходе;
- проверить текст SQL-запроса, соответствующий текущему шагу.
Группировка
Шаблон «Группировка» позволяет агрегировать данные из таблицы-источника или таблицы предыдущего шага. Соответствует SQL-операции GROUP BY.
На следующем рисунке рассчитана сумма по полю «Сумма» для каждого значения поля «Товар».
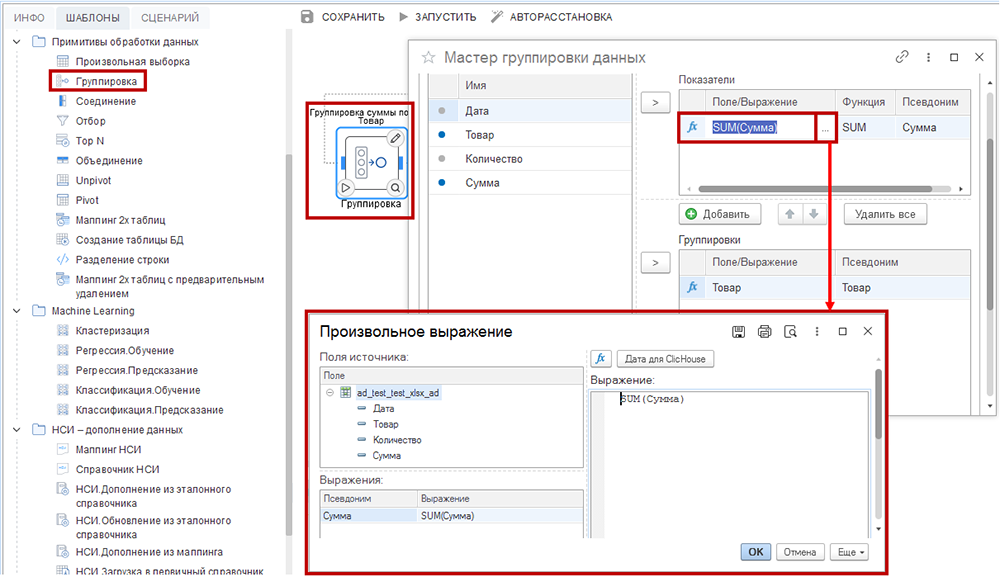
Группируемые поля («Товар») перемещаются из левой секции «Поля источника» в нижнюю правую («Группировки») с помощью мыши (методом drag-and-drop). Точки напротив имен использованных полей меняют цвет на синий.
Кнопки со стрелками над секцией «Группировки» позволяют менять порядок группируемых полей сверху вниз. Это влияет на их порядок в новой таблице слева направо (соответственно).
Для настройки агрегаций (например, суммы, среднего, максимума, минимума или количества строк) переместите нужные поля из левой секции «Поля источника» в верхнюю правую секцию «Показатели» с помощью мыши.
Как изменить порядок строк:
- Нажмите правой кнопкой мыши на строку в секции «Показатели».
- В контекстном меню выберите «Переместить вверх» или «Переместить вниз».
Двойной щелчок мыши по полю в «Показатели» и нажатие кнопки «…» открывает диалоговое окно «Произвольное выражение». В окне вы можете вручную прописать код SQL для агрегации («Выражение»).
В каждой строке секций «Группировки» и «Показатели» есть столбец «Псевдоним». В столбце вы можете вручную ввести новое название колонки.
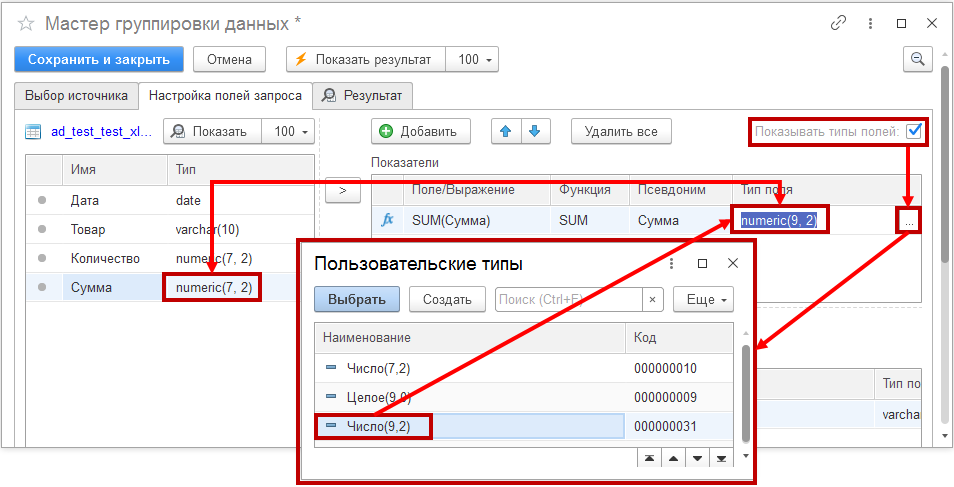
По умолчанию, агрегируемому выражению в секции «Показатели» присваивается тот же числовой тип, что и у исходного поля. На вкладке доступен селектор «Показывать типы полей», который рекомендуется включить. Это позволит изменять тип чисел в агрегации.
Если суммы в исходной таблице большие, может потребоваться тип с большей разрядностью, чтобы итоговый расчет не вышел за пределы диапазона исходного поля. В противном случае результатом группировки может стать ошибка.
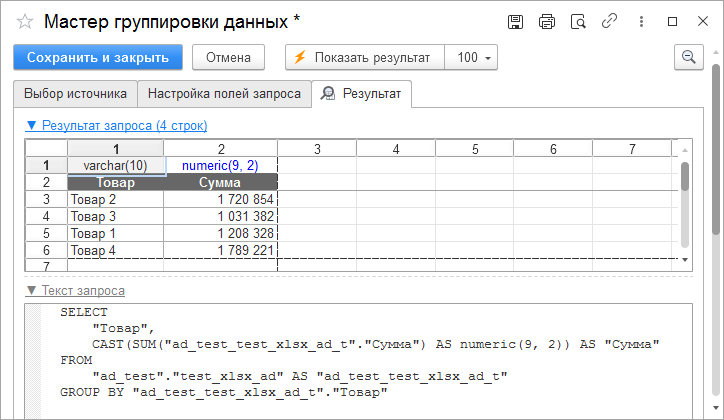
Результат шага отображается на вкладке «Результат»: возможно увидеть полученную таблицу и код SQL для ее генерации.
Соединение
Шаблон «Соединение» используется для объединения данных из нескольких таблиц. Для шага с таким шаблоном нужны связи из предыдущих шагов (например, таблиц-источников или вычисляемых таблиц с помощью примитивов). Должно быть минимум две таблицы для объединения. Рассмотрим пример соединения «Левое» (аналог функции ВПР в MS Excel / операции LEFT JOIN в SQL) — к таблице продаж по адресу необходимо добавить почтовый индекс.
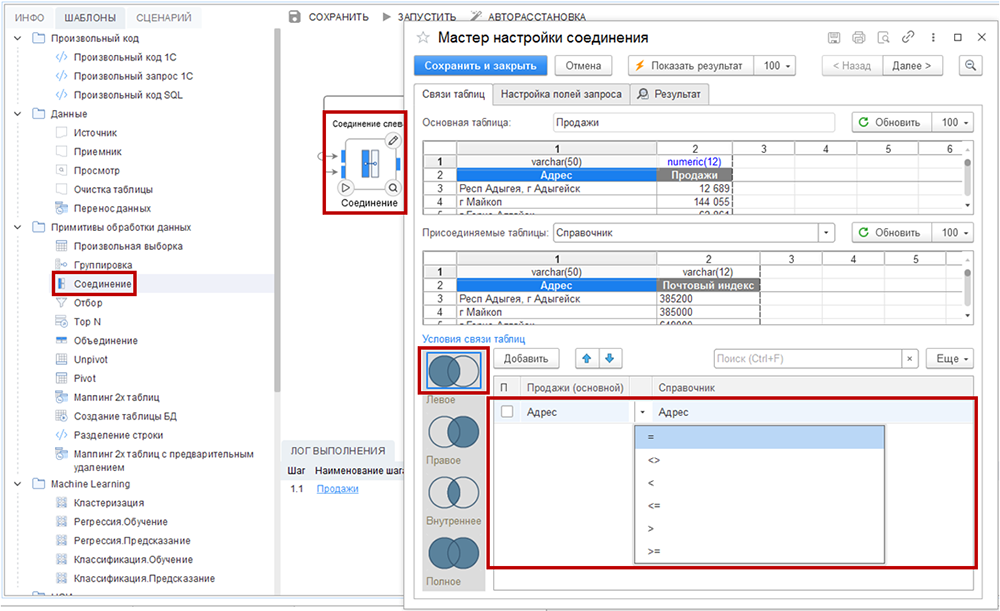
Настройка соединения таблиц:
- В нижней секции «Условия связи таблиц» выберите тип соединения (например, «Левое»).
- Нажмите на кнопку «Добавить» и задайте условие равенства для двух полей (например, «Адрес»).
- В колонках «Продажи (основной)» и «Справочник» выберите поле «Адрес» из выпадающих списков.
- В столбце между полями выберите вид условия (например, равенство «=»).
Если ключ связи составной, добавьте дополнительные строки условий, нажимая на кнопку «Добавить».
Объединение нескольких таблиц:
- В выпадающем списке «Присоединяемые таблицы» выберите третью, четвертую и т.д. таблицы.
- Задайте связи между полями в секции «Условия связи таблиц» аналогичным образом.
Выбор полей для итоговой таблицы:
- Перейдите на вкладку «Настройка полей запроса».
- В левой секции отображаются исходные таблицы и их поля.
- Перетащите нужные поля в правую секцию с помощью мыши (drag-and-drop) или кнопок «>» и «<».
- Точки напротив выбранных полей изменят цвет на синий, указывая на их использование.
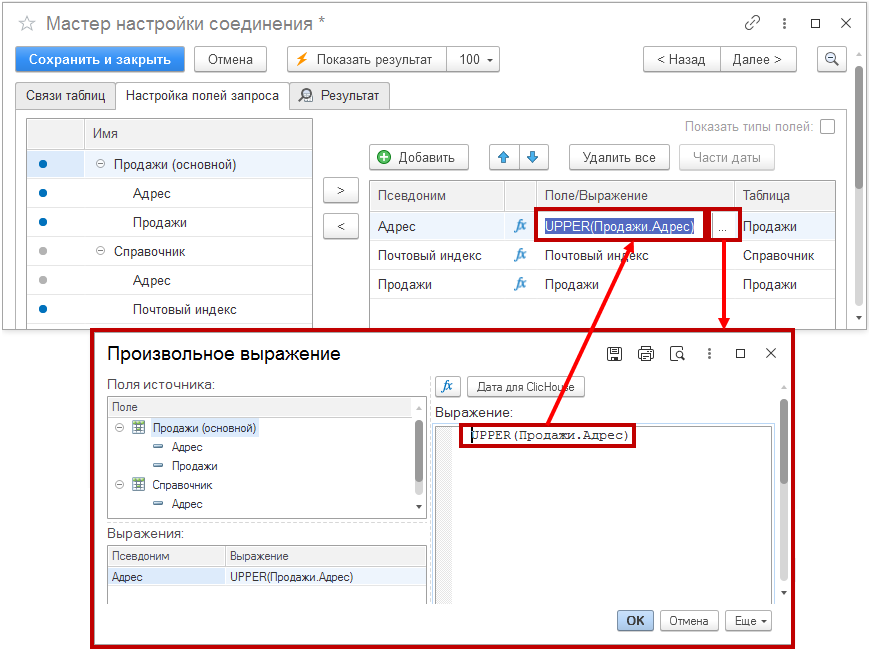
Настройка порядка и выражений:
- Используйте кнопки со стрелками над правой секцией, чтобы изменить порядок группируемых полей сверху вниз. Это влияет на их расположение в итоговой таблице (слева направо).
- Кнопка «Добавить» позволяет создать новую строку для выражения.
- Двойной щелчок мыши по столбцу «Поле/Выражение» и нажатие кнопки «…» открывает диалоговое окно «Произвольное выражение».
- В окне возможно вручную написать SQL-код для расчета нового показателя (например, перевод адреса продаж в верхний регистр).
- В столбце «Псевдоним» возможно вручную задать новое название для колонки.
- Трансформация полей с датой и временем:
- Добавьте поле с датой в правую секцию.
- Выделите его и нажмите на кнопку «Части даты».
- В появившемся окне выберите нужный вариант (например, извлечение месяца или года).
- После добавления трансформированного результата исходное поле с датой можно удалить.
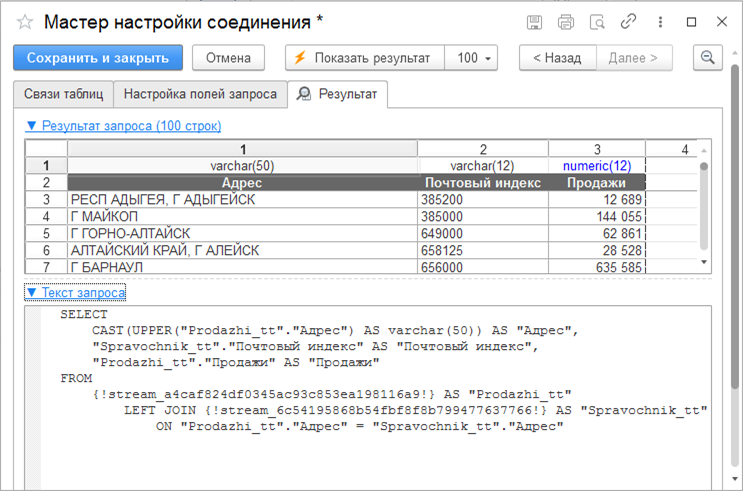
Таблица, генерируемая шаблоном, отражается на вкладке «Результат». Здесь вы можете увидеть также код SQL для генерации данных.
Отбор
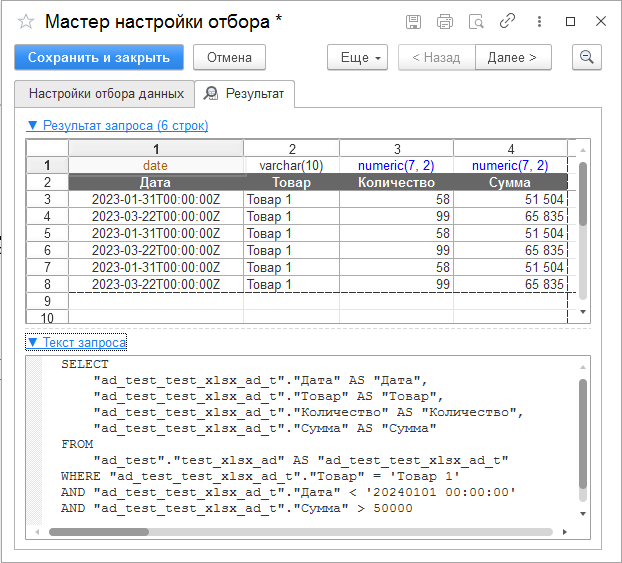
Шаблон «Отбор» используется для фильтрации таблицы по одному или группе полей, в логике SQL соответствует оператору WHERE. Для настройки выберите поля из таблицы предыдущего шага и укажите условия фильтрации (одно или более). При этом выводятся все колонки исходной таблицы — их нельзя извлекать выборочно или производить над ними вычисления.
Примечание — на пиктограмме шага два выхода на следующие шаги:
- Верхний выход (✔) - передает данные, соответствующие условию отбора.
- Нижний выход (✖) - передает данные, не прошедшие отбор.
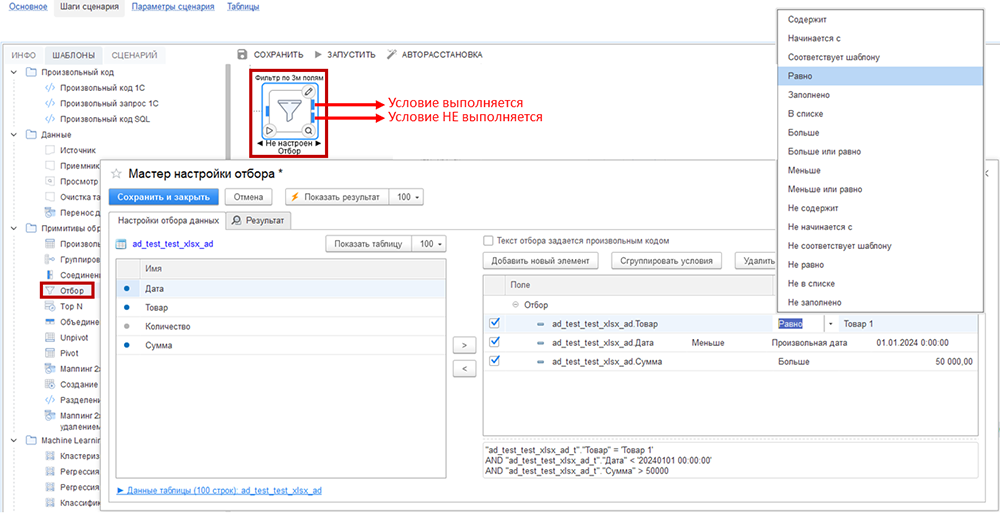
На рисунке выше исходная таблица предыдущего шага фильтруется одновременно по трем полям:
- наименование товара должно быть «Товар 1»;
- дата продаж до 01.01.2024;
- сумма продаж в каждой строке больше 50 000 руб.
Настройка отбора данных:
- Вкладка «Настройка отбора данных» разделена на две секции:
- Левая секция: Источник данных.
- Правая секция: Условия отбора для новой таблицы, создаваемой шагом сценария.
- Добавление полей для фильтрации:
- Переместите нужные поля из левой секции в правую с помощью мыши (drag-and-drop) или кнопок «>» и «<».
- Точка напротив использованных полей в исходной таблице изменит цвет на синий.
- Работа с правой секцией:
- Добавляйте или удаляйте поля с условиями фильтрации с помощью кнопок «Добавить новый элемент», «Удалить» и «Сгруппировать условия».
- Меняйте порядок условий сверху вниз с помощью кнопок со стрелками над секцией.
- Задавайте тип сравнения, дважды щелкнув по полю и выбрав значение из выпадающего списка.
- Для дат доступны различные варианты (например, «Начало прошлого года», «Начало этого дня» и т.д.).
- В колонке «Значение» введите константу и активируйте галочку перед именем поля.
- Активируйте режим «Текст отбора задается произвольным кодом», чтобы вручную ввести SQL-код отбора.
- На вкладке «Результат» вы можете:
- Посмотреть итоговую таблицу.
- Проверить SQL-запрос, соответствующий текущему шагу.
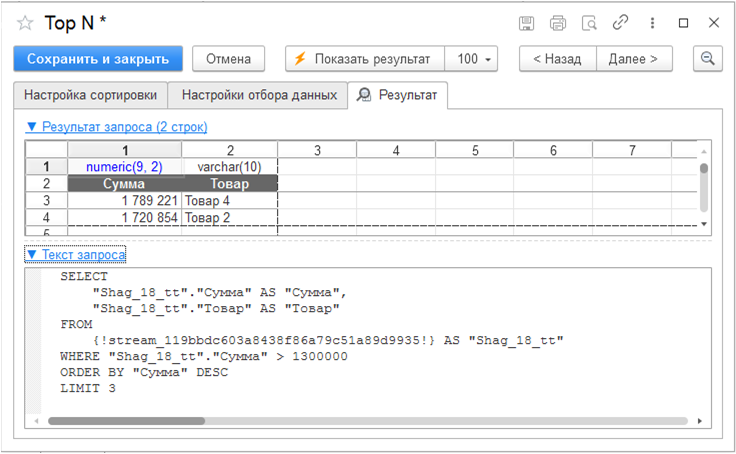
Top N
Шаблон «Top N» извлекает из таблицы исходных данных первые N записей, аналогичен оператору SQL LIMIT и дополнительно поддерживает фильтрацию и сортировку.
Шаблон полезен, когда нужно выбрать N «лучших» или «худших» записей на основе отсортированного поля.
Рассмотрим пример, где на предыдущем шаге создана таблица следующего вида:
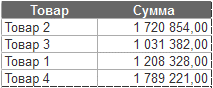
Выберем три самых продаваемых товара, но с суммой продаж более 1 300 000 руб. Отсортируем таблицу по полю «Сумма» и три записи с фильтром по полю «Сумма» от 1 300 000.
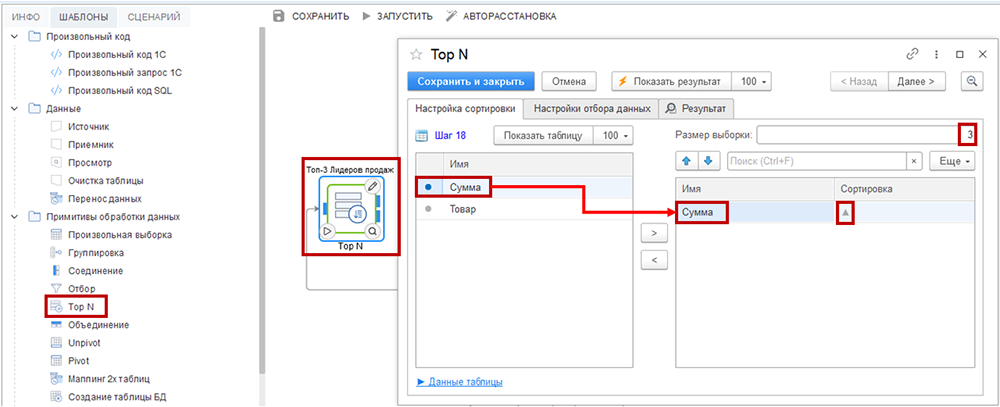
На первом шаге укажите поле для сортировки. Вкладка «Настройка сортировки» имеет две секции: левую (источник данных) и правую (условия отбора для новой таблицы, которую создает шаг сценария).
Переместите нужные для фильтрации поля из левой секции в правую с помощью мыши (методом drag-and-drop), или кнопок «>» и «<». Точка напротив использованных полей в исходной таблице меняет цвет на синий (в данном случае поле «Сумма»).
В правой секции вы можете:
- менять порядок условий сверху вниз (кнопками со стрелками над секцией). Это важно, потому что можно одновременно сортировать более одного поля. Порядок полей сверху вниз влияет на очередность сортировки: сортировка полей, которые выше, приоритетнее, чем тех, которые ниже;
- добавлять, удалять поля с условиями фильтрации. Для этого предусмотрено контекстное меню, вызываемое правой кнопкой мыши;
- задавать тип сортировки двойным щелчком мыши по колонке «Сортировка». Сортировать можно по убыванию или возрастанию (в данном случае логично по убыванию). В колонке »Сортировка» появится знак треугольника соответствующей формы.
В поле «Размер выборки» введем цифру «3».
На следующем шаге зададим фильтрацию на вкладке «Настройка отбора данных«.
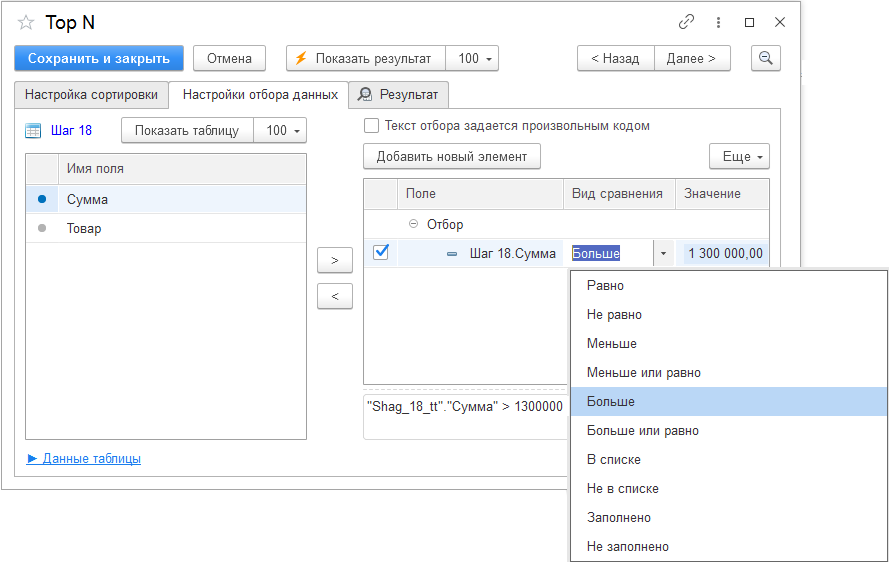
Здесь также есть две секции: левая (список полей исходной таблицы с предыдущего шага) и правая (условия отбора для полей).
Переместите нужные для фильтрации поля из левой секции в правую с помощью мыши, или кнопок «>» и «<». Точка напротив использованных полей в исходной таблице меняет цвет на синий (в данном случае поле «Сумма»).
В правой секции вы можете:
- добавлять, удалять поля с условиями фильтрации. Для этого предусмотрено контекстное меню, вызываемое правой кнопкой мыши, и кнопка «Добавить новый элемент» над секцией;
- выбрать тип сравнения из выпадающего списка в колонке «Вид сравнения»;
- задать вручную пограничное значение в поле «Значение».
Для дат есть множество вариантов: «Произвольная дата» (с выбором из календаря), «Начало прошлого года», «Начало этого дня» и т.д. для дней, недель, месяцев и лет.
На вкладке «Результат» возможно посмотреть, какая таблица получится на выходе и какой текст запроса на SQL соответствует всему шагу.
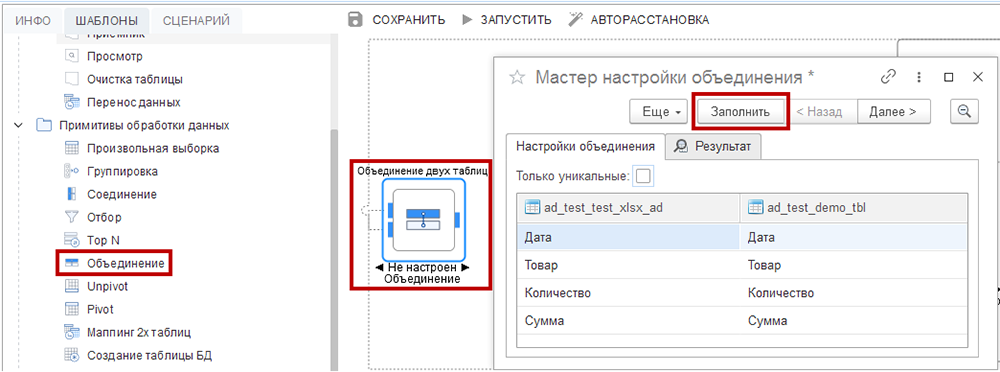
Объединение
Шаблон «Объединение» позволяет объединить разные таблицы из предыдущих шагов построчно. Соответствует логике SQL-оператора UNION.
На первом шаге (вкладка «Настройки объединения») укажите, как поля из разных таблиц соответствуют друг другу. На вкладке отображается таблица-конструктор, где каждая колонка представляет поля таблиц, участвующих в объединении (их может быть больше двух).
Если поля таблиц имеют одинаковые названия и типы данных, возможно ускорить процесс с помощью кнопки «Заполнить»: она автоматически выполнит расстановку соответствий. Если требуется корректировка, в каждой ячейке доступен раскрывающийся список, где возможно вручную выбрать нужное поле.
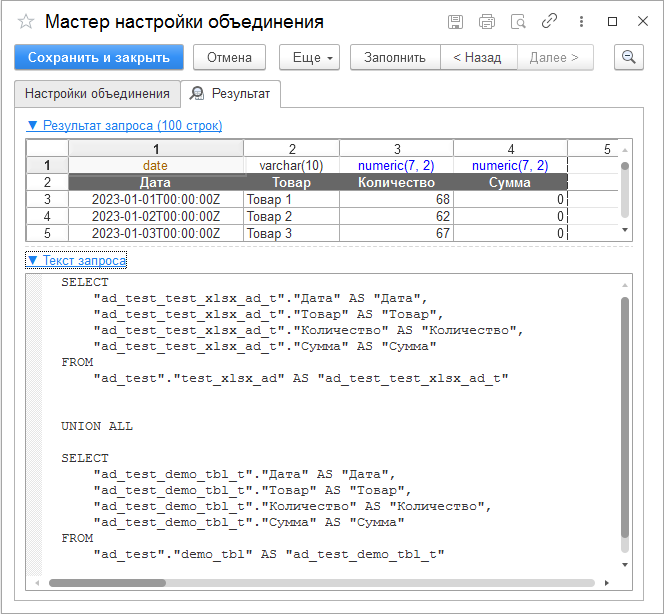
При включенном селекторе «Только уникальные» из итоговой (объединенной) таблицы удаляются повторяющиеся строки. В коде SQL из оператора UNION исключается параметр ALL.
На вкладке «Результат» возможно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует всему шагу.
Unpivot
Шаблон «Unpivot» выполняет действия, обратные шаблону «Pivot», преобразуя столбцы данных в строки. Соответствует одноименному оператору SQL.
Например, есть данные о продаже товаров помесячно следующего вида.
![]()
На следующем рисунке — пример настройки шаблона.
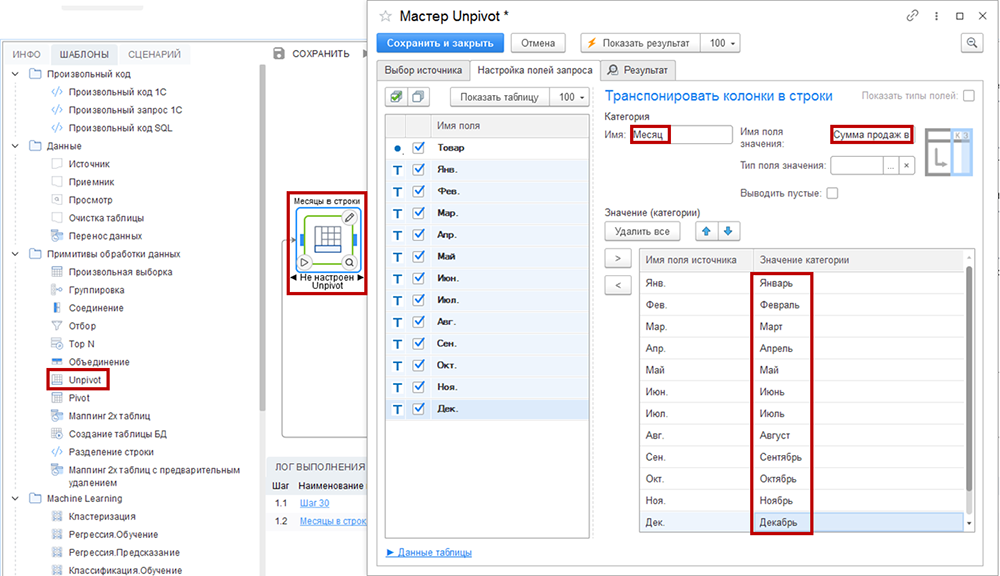
В левой секции окна настройки шаблона выделены все поля, поскольку они все задействованы.
На вкладке «Настройка полей запроса» в имени «Категория» введите «Месяц», а в «Имя поля значения» введите «Сумма продаж в руб.». В нижнюю правую секцию «Значение (категория)» переместите (мышью методом «drag-and-drop» или кнопками «<» и «>») поля с месяцами, и напротив каждого месяца возможно вручную ввести полное наименование. С помощью контекстного меню удалите лишние поля из списка.
Если галочка «Выводить пустые» установлена, то строки со значениями NULL будут выведены, в противном случае, строки не выводятся.
В «Тип поля значения» возможно скорректировать тип (например, увеличить разрядность чисел, чтобы не было переполнения).
На вкладке «Результат» возможно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует всему шагу.
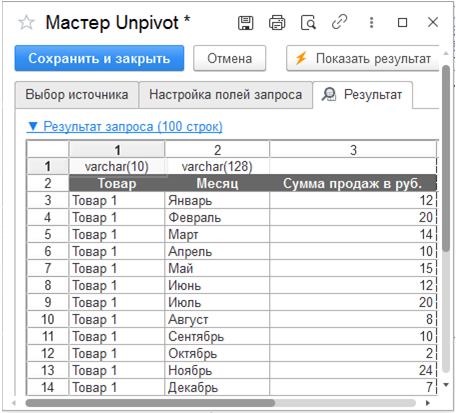
Pivot
Шаблон «Pivot» производит действия, обратные шаблону «Unpivot»: он преобразует строки данных в столбцы. Соответствует одноименному оператору SQL. Например, есть данные о продаже товаров помесячно следующего вида:
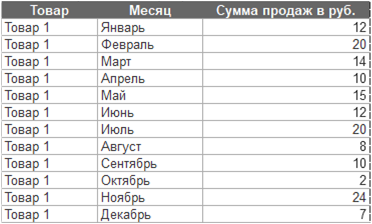
Требуется данные с названиями месяцев перевести в столбцы. В окне настройки шаблона есть четыре секции:
- «Поля источника» — перечень полей исходной таблицы;
- «Строки (группировки)» — для полей, которые останутся в столбцах (в данном случае поле «Товар»);
- «Столбцы» — для поля, которое из столбца трансформируется в строки («Месяц»);
- «Значения» — числовое поле со значениями («Сумма продаж в руб.»).
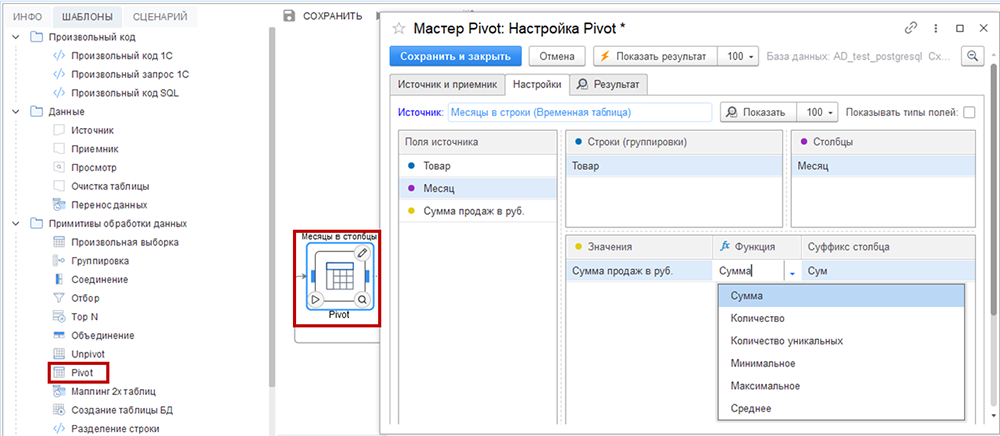
Поля из секции «Поля источника» добававьте в другие три секции с помощью мыши методом drag-and-drop. Слева от названия полей, использованных в секции «Поля источника», появляется цветная точка.
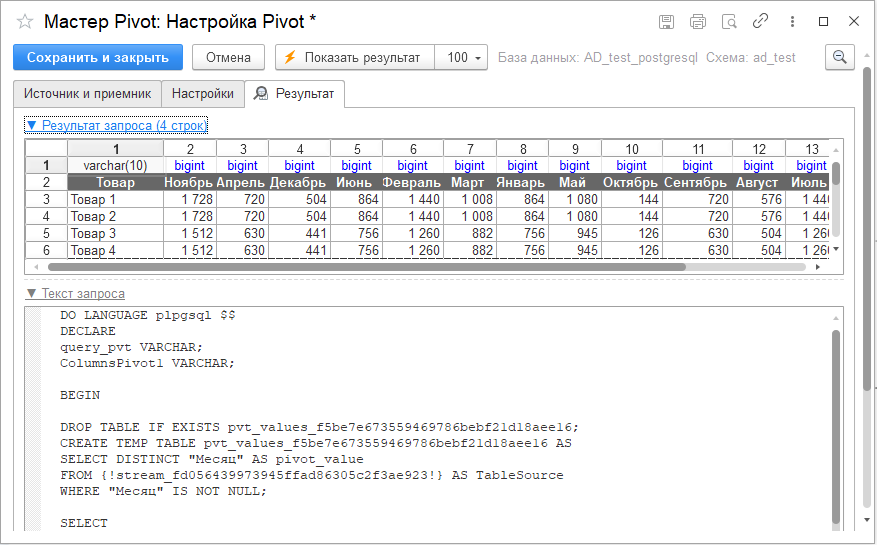
В процессе трансформации для числового поля возможно выбрать агрегацию (сумма, количество, число уникальных значений, минимум, максимум и среднее). Такая возможность может быть актуальна, если для комбинаций полей в «Столбцы» и «Строки (группировки») есть много записей. Например, если бы в исходной таблице записи повторялись для одних и тех же товаров в одном месяце, но по дням месяца. В некоторых случаях, в принципе, для исследования данных интересны аналитики типа среднего, максимум, минимума и т.д.
В рассматриваемом примере выбирается вариант суммирования, и укрупнения информации не произойдет.
На вкладке «Результат» возможно посмотреть, какая таблица получится на выходе, и какой текст запроса на SQL соответствует всему шагу.
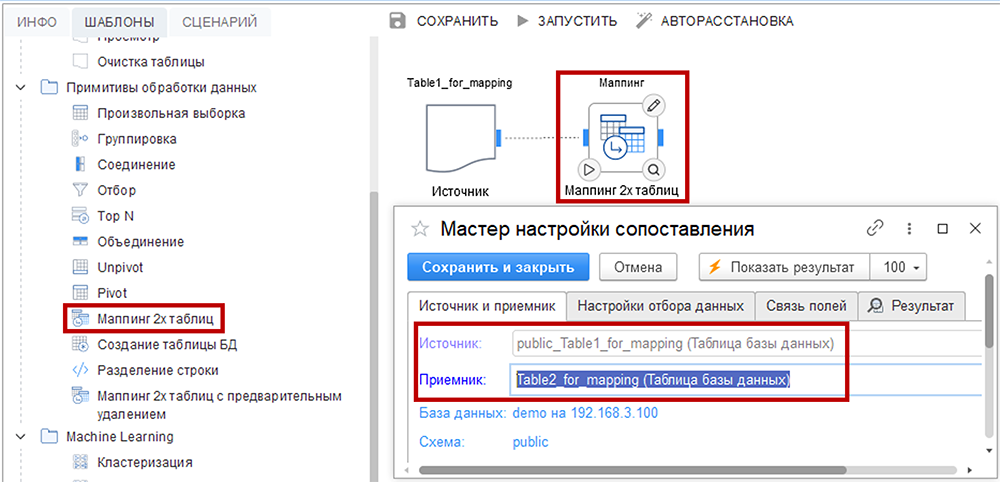
Маппинг 2х таблиц
Шаблон «Маппинг 2х таблиц» позволяет копировать данные из одной таблицы в другую, используя настроенные правила соответствия (маппинг) полей. С его помощью возможно указать, какие поля исходной таблицы соответствуют полям целевой таблицы в рамках SQL-инструкции INSERT INTO. Также доступны функции фильтрации исходных данных и выполнения простых преобразований.
Например, возможно скопировать данные из таблицы-источника в таблицу-приемник, исключив данные по округу ЮФО. При этом поле «Регион» в таблице-источнике будет соответствовать полю «Область» в таблице-приемнике.

На вкладке «Источник и приемник» выберите имена двух таблиц в базе данных.
Округ ЮФО отфильтрован на вкладке «Настройки отбора данных».
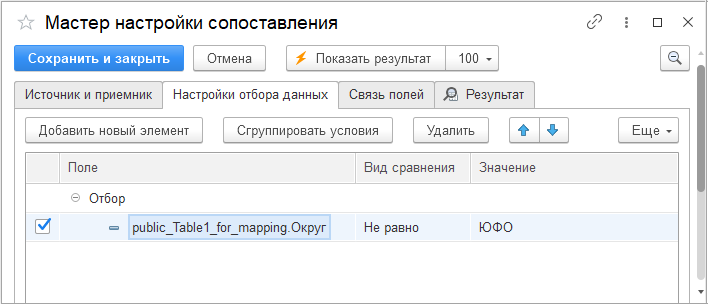
Для создания отбора нажмите «Добавить новый элемент» (правее есть кнопки группировки условий и удаления). Затем укажите поле для отбора, вид сравнения (из выпадающего списка) и в колонке «Значение» введите константу.
Вы можете задать сразу множество отборов, а также группировать их (когда условия выполняются одновременно — логическое «И», не выполняются — логическое «НЕ», либо достаточно выполнения одного любого условия из группы — логическое «ИЛИ»). Для этого выделите несколько условий и нажмите на кнопку «Сгруппировать условия», затем выберите в заголовке группы нужный логический вариант.
Далее, на вкладке «Связь полей» установите связь полей (рисунок ниже). Из левой секции «Источник» (где есть перечень полей таблицы-источника) с помощью мыши методом drag-and-drop переместите нужные поля в правую секцию «Приемник». Если поля называются одинаково, возможно воспользоваться кнопкой «Автосопоставление». Предусмотрена кнопка и быстрой очистки сопоставлений. Над обоими секциями есть кнопки «Показать таблицу» для предварительного просмотра данных.
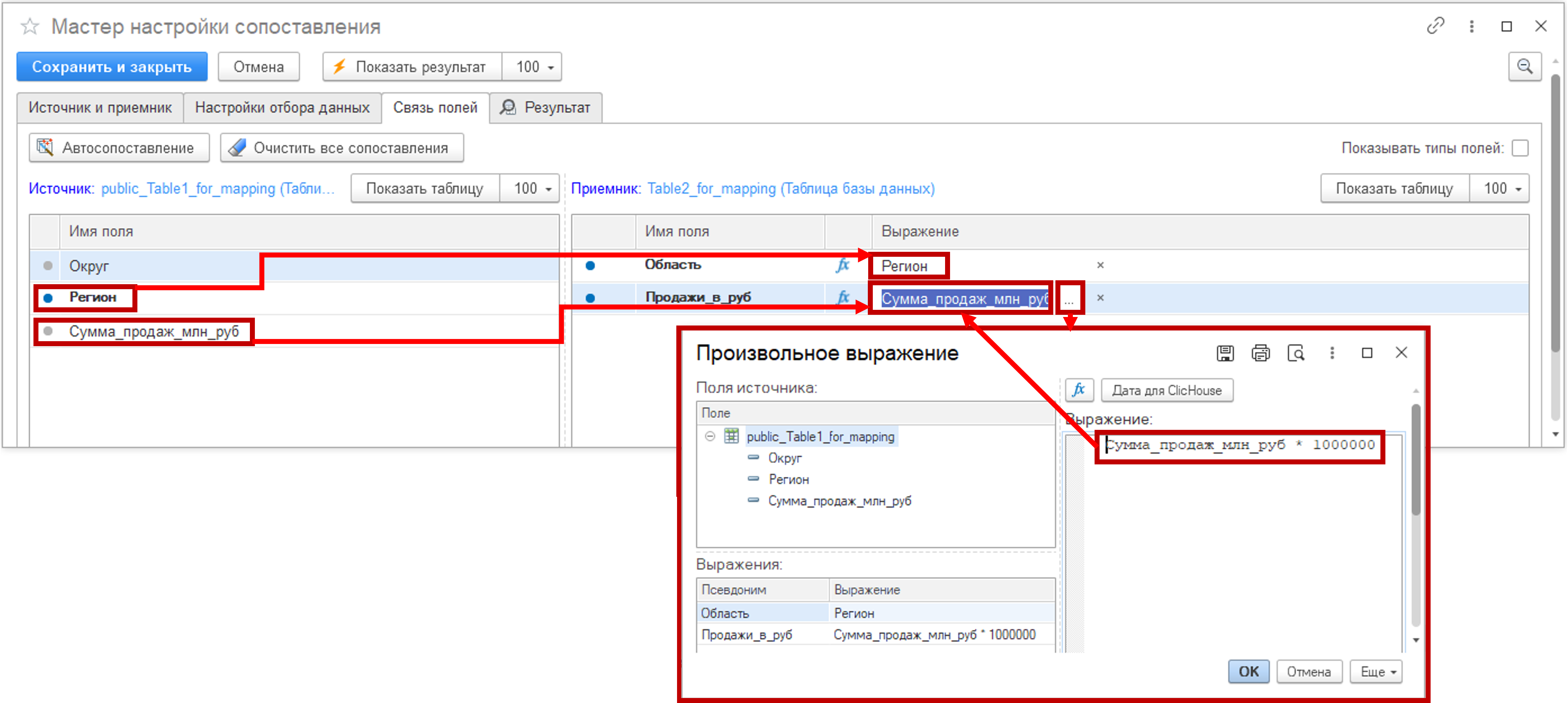
Чтобы суммы продаж были в одном измерении, поле таблицы-источника «Сумма_продаж_млн_руб.» перед копированием в поле «Продажи_в_руб.» таблицы-приемника надо умножить на 1000000. После двойного щелчка мышью по имени перемещенного поля в правой секции («Сумма_продаж_млн_руб.») появится кнопка «…», которая вызовет диалоговое окно «Произвольное выражение». В этом окне возможно ввести необходимую формулу для вычислений.
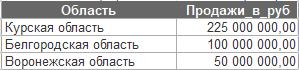
После выполнения шага маппинга возможно получить необходимый результат (рисунок ниже).
Создание таблицы БД
Шаблон «Создание таблицы БД» позволяет создать пустую таблицу базы данных с определенным набором полей нужного типа. Для шаблона не нужны предыдущие шаги, чтобы получить входные данные. Такой шаг соответствует SQL-оператору CREATE TABLE.
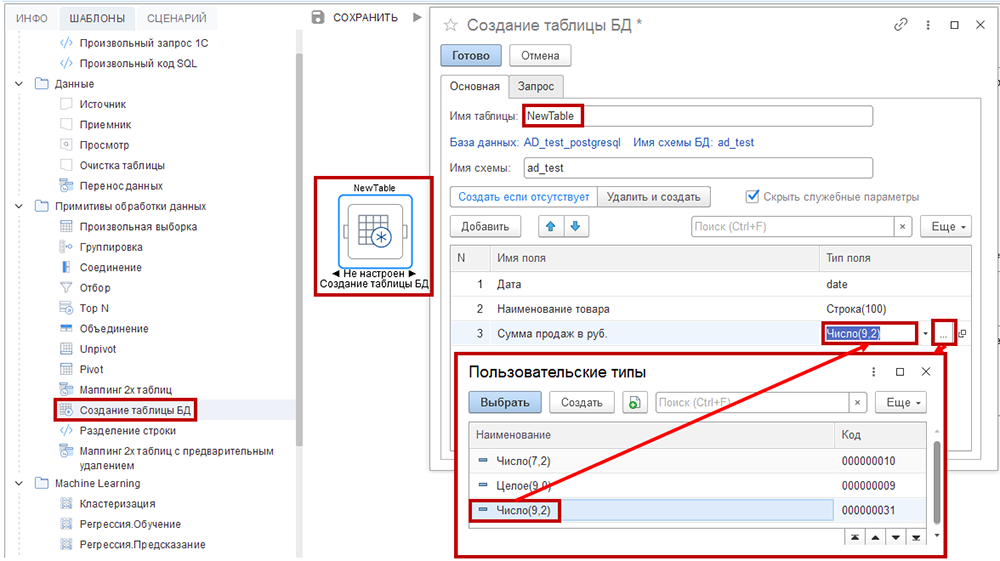
На вкладке «Основная» укажите «Имя таблицы», схему и нажмите на кнопку «Добавить», чтобы создать поле. В колонке «Имя поля» вручную введите имя поля. Дваждый щелкните мышью в колонке «Тип поля», появится кнопка «…», нажмите на нее, чтобы задать тип из категории «Типы данных» или «Пользовательские типы».
Клавиши со стрелками вверх и вниз меняют порядок полей в новой таблице слева-направо соответственно.
На вкладке «Основная» также предусмотрен селектор «Создать если отсутствует» и «Удалить и создать». Выбранный режим выделяется синим цветом текста и влияет на алгоритм шаблона: в первом случае таблица просто создается с нуля, если её нет, во втором случае она всегда удаляется и заново создается.
Селектор «Скрыть служебные параметры» скрывает настройки: подтип данных для поля, и допускаются ли пустые значения (NULL) в конкретном поле.
Результат работы шаблона (вкладка «Результат») — код на PostgreSQL.
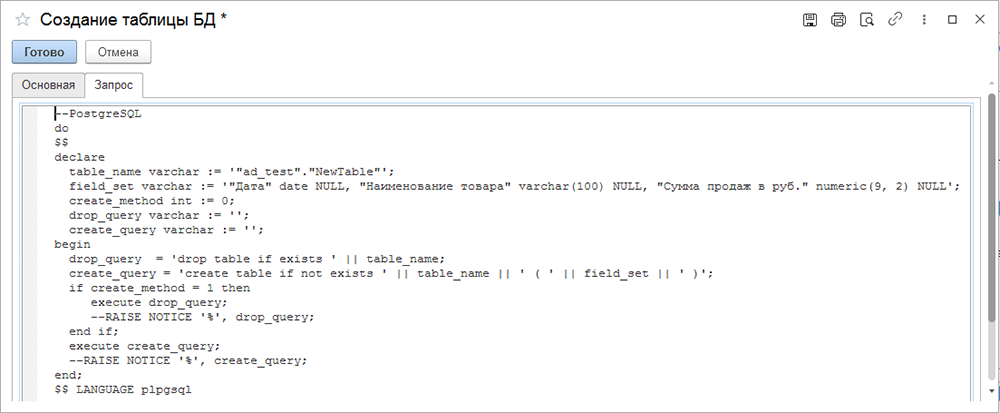
Кнопка «Готово» в верхнем левом углу шаблона завершает настройку шага.
Разделение строки
Шаблон «Разделение строки» разделяет строки на массив подстрок, используя указанный разделитель. В таблице на выходе становится больше строк, так как строки исходной таблицы разделяются на части в том месте, где есть разделитель.
Шаблон соответствует оператору UNNEST с параметром STRING_TO_ARRAY, которые специфичны для PostgreSQL.
Такой шаг может быть полезен для анализа данных, значения которых разделены определенным символом. Например, встречаются выгрузки в формате «CSV» в которых наборы данных в тексте разделены запятой.
Рассмотрим пример, когда на метеостанциях ежедневно, 6 раз в сутки, снимаются показания температуры.
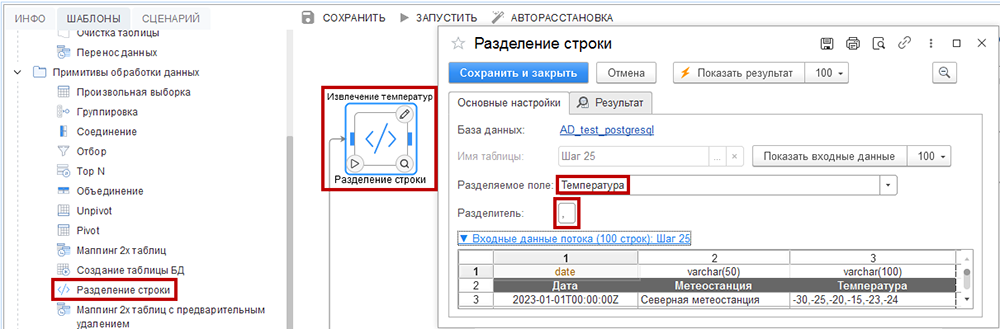
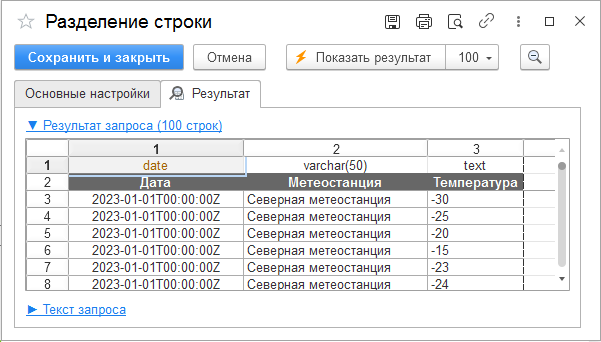
Нажмите на кнопку «Показать входные данные», чтобы выгрузить в нижней секции пример исходной таблицы. Из списка полей «Разделяемое поле» выберите «Температура» и укажите «Разделитель» («,»).
Ниже — результат работы шага на вкладке «Результат». Из каждой строки исходной таблицы получилось шесть строк. Значения полей «Дата» и «Метеостанция» дублируются для каждой новой строки, а поле «Температура» разделено на шесть значений.
Маппинг 2х таблиц с предварительным удалением
Шаблон «Маппинг 2х таблиц с предварительным удалением» работает аналогично шаблону «Маппинг 2х таблиц», но с одним важным отличием. На вкладке «Связь полей» задаются ключевые поля для поиска (в колонке «Поиск»).
Все записи из таблицы-источника будут перенесены в таблицу-приемник. Если записи совпадут по ключу поиска, они будут заменены соответствующими записями из таблицы-источника.
Очистка таблицы
Шаблон «Очистка таблицы» необходим для очистки таблицы.
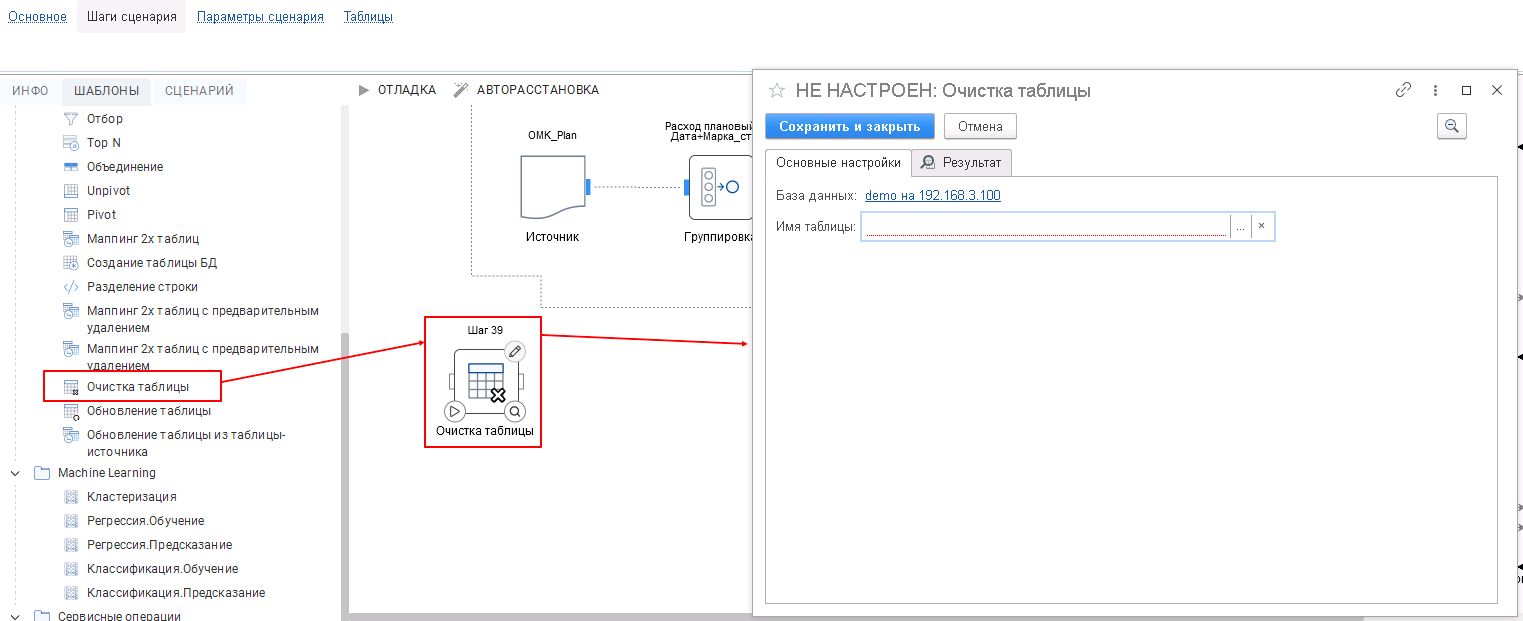
Выберите имя таблицы, которую необходимо очистить и нажмите на «Сохранить и закрыть». Результат будет оформлен в виде текста запроса, например, truncate table [DWH].[dbo].[__File].
Обновление таблицы
Шаблон «Обновление таблицы» позволяет обновлять данные в существующих таблицах хранилища в соответствии с настраиваемыми параметрами. На вкладке «Шаги сценария» добавьте шаг «Обновление таблицы». Данный шаг по типу связи «Передача управления» позволяет обновить определенную таблицу, а также настроить параметры таблицы (тип данных и поле/ выражение). Данный шаг нужен для того, чтобы в определенной таблице изменить параметры, например, перемножить данные.
В настройках шага отображается вкладка «Выбор источника». В отобразившейся форме выберите источник, который будем настраивать. Если шаг сценария связан с предыдущим, то источником будет таблица, созданная на предыдущем шаге (например, с помощью шаблона «Источник» или других примитивов обработки данных).
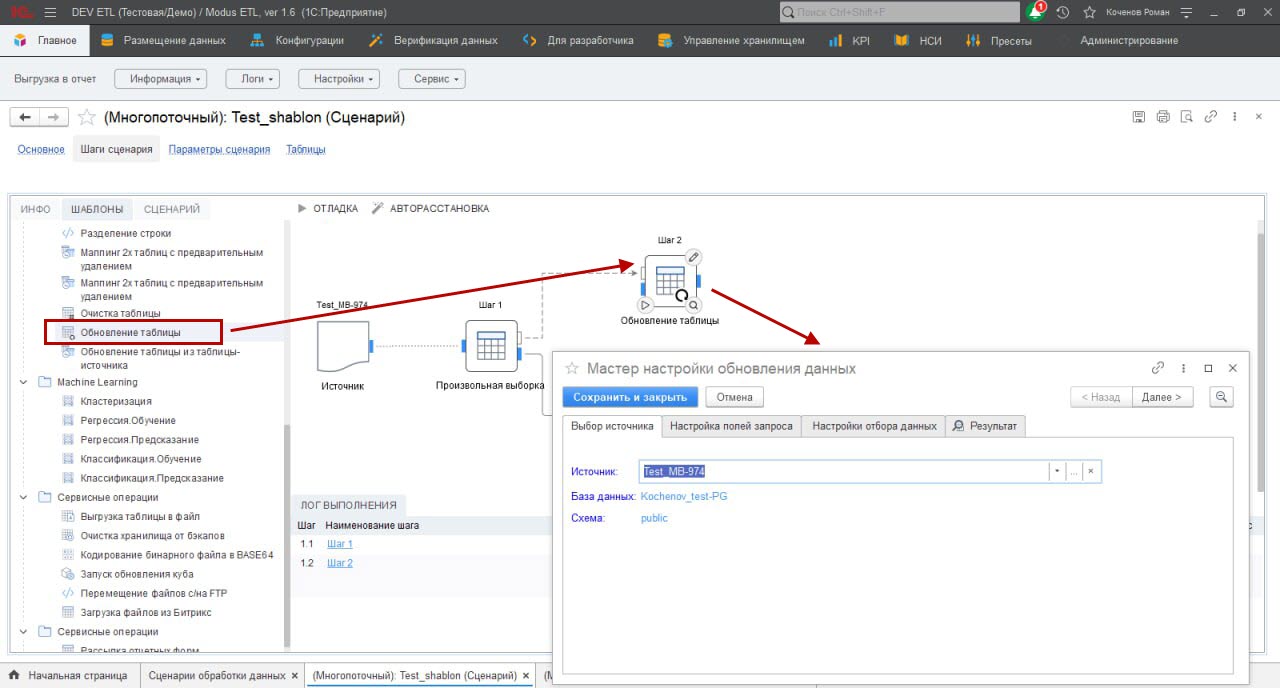
На вкладке «Настройка полей запроса» настройте поля запроса.
Как в большинстве шаблонов группы, вкладка имеет две секции: левую (источники данных) и правую (поля новой таблицы, которую обновляет шаг сценария).
Нужные для выборки поля перемещаются из левой секции в правую с помощью мыши (методом drag-and-drop), или кнопок «>» и «<». Точка напротив использованных полей в исходной таблице меняет цвет на синий.
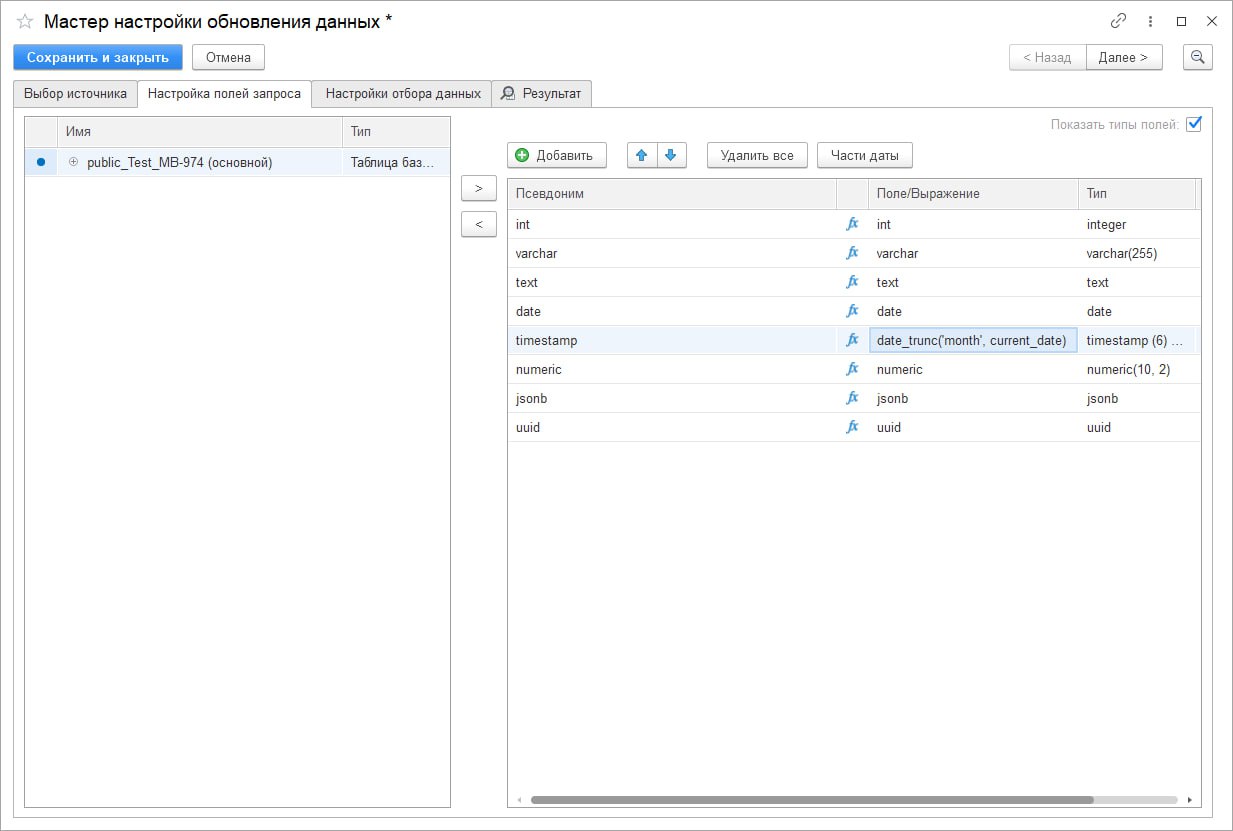
В правой секции вкладки «Настройка полей запроса» вы можете:
- добавлять, удалять поля новой таблицы. Предусмотрены кнопки «Добавить» и «Удалить все»;
- менять порядок полей сверху вниз (кнопками со стрелками над секцией). Это влияет на порядок полей слева направо (соответственно) формируемой таблицы;
- задавать псевдоним нового поля ручным вводом в колонке «Псевдоним» (по умолчанию имена полей совпадают с исходными, либо генерируются автоматически при создании части даты);
- трансформировать выражения, производить дополнительные расчеты с помощью вставок кода на SQL. Для этого в колонке «Поле/Выражение» дважды щелкните мышью, появится кнопка с символом троеточия «…». Нажмите на нее и в открывшейся форме «Произвольное выражение» вручную введите код;
- менять тип полей в новой таблице с помощью колонки «Тип». Интерфейс аналогичный колонке «Поле/Выражение» — двойной щелчок мыши и кнопка «…».
При необходимости возможно настроить фильтрацию данных в исходной таблице по заданным условиям. Для этого перейдите на вкладку «Настройка отбора данных».
Как настроить отбор:
- Нажмите на кнопку «Добавить новый элемент» (справа также доступны кнопки для группировки условий и удаления).
- Укажите поле для отбора, выберите вид сравнения и введите значение в колонке «Значение».
Возможно задать сразу несколько отборов для более точной фильтрации данных.
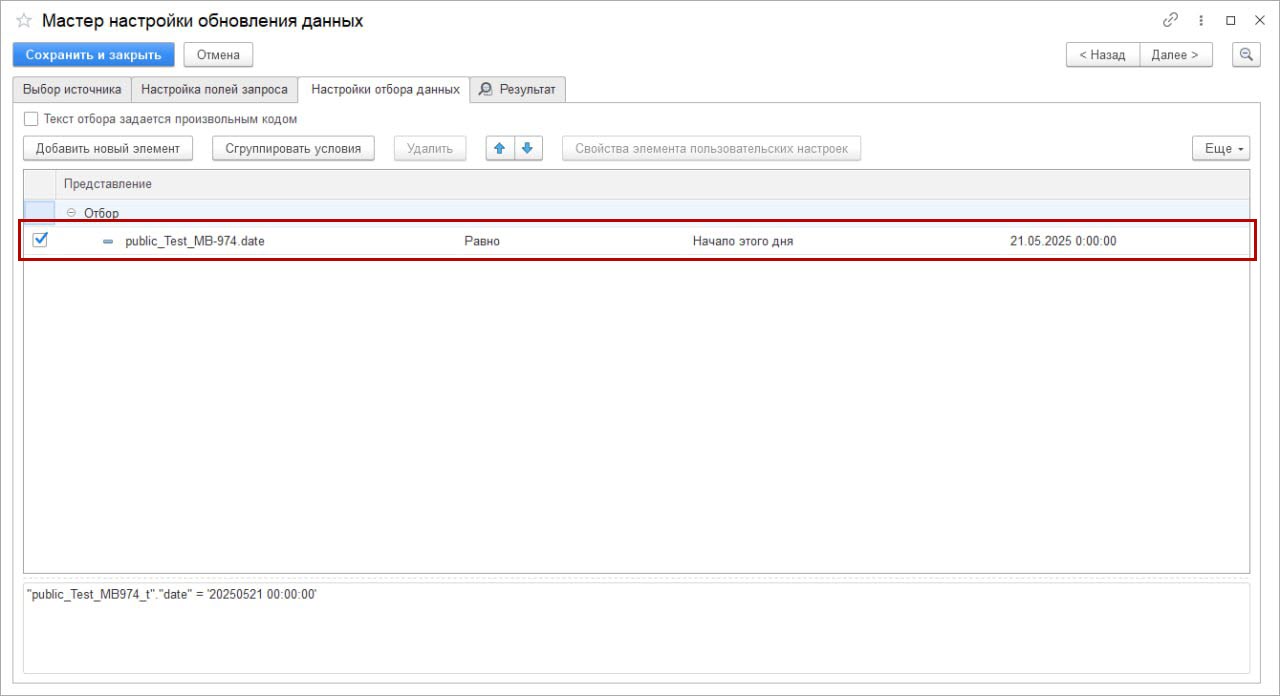
Для настройки сложных условий фильтрации возможно использовать группировку условий:
- логическое «И» — все условия в группе должны выполняться одновременно.
- логическое «НЕ» — ни одно из условий в группе не должно выполняться.
- логическое «ИЛИ» — достаточно выполнения хотя бы одного условия из группы.
Как настроить группировку:
- Выделите несколько условий.
- Нажмите на кнопку «Сгруппировать условия».
- Выберите нужный логический вариант в заголовке группы.
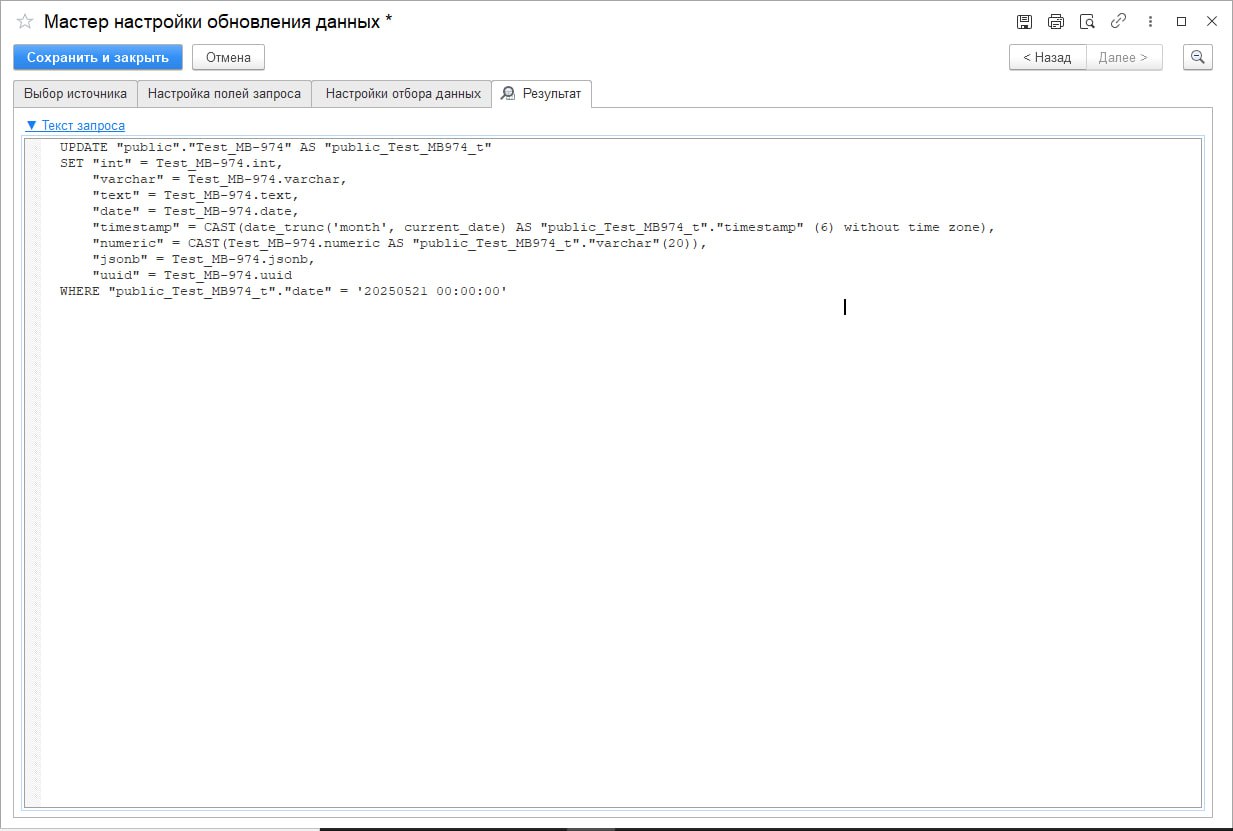
На вкладке «Результат» вы можете:
- посмотреть, какая таблица получится на выходе;
- проверить текст SQL-запроса, соответствующий текущему шагу.
Обновление таблицы из таблицы-источника
Шаблон «Обновление таблицы из таблицы-источника» позволяет обновить данные одной существующей таблицы хранилища на основании данных другой таблицы хранилища или на основании входящего потока со вложенным запросом. На вкладке «Шаги сценария» добавьте шаг «Обновление таблицы». По умолчанию в настройках шага отображается вкладка «Источник и приемник».
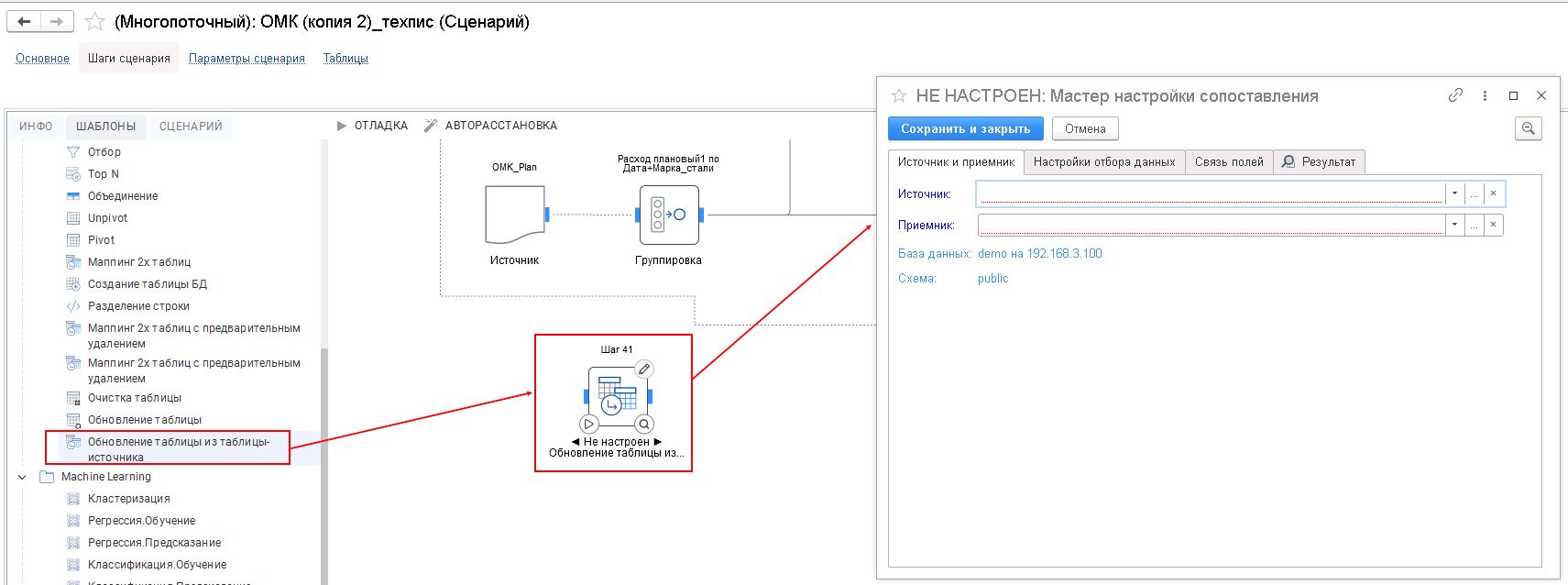
Сначала задается один обязательный источник данных, который отображается на первой вкладке «Выбор источника». Если шаг сценария связан с предыдущим, то источником будет таблица, созданная на предыдущем шаге (например, с помощью шаблона «Источник» или других примитивов обработки данных). Также укажите обязательный приемник таблицы.
При необходимости возможно настроить фильтрацию данных в исходной таблице по заданным условиям. Для этого перейдите на вкладку «Настройка отбора данных».
Как настроить отбор:
- Нажмите на кнопку «Добавить новый элемент» (справа также доступны кнопки для группировки условий и удаления).
- Укажите поле для отбора, выберите вид сравнения и введите значение в колонке «Значение».
Возможно задать сразу несколько отборов для более точной фильтрации данных.
В примере ниже введено условие [dbo__dbo___FO_Kompaniy_period__t].[Условное_обозначение] LIKE '%5%', как указано в SQL-коде в нижней части окна.
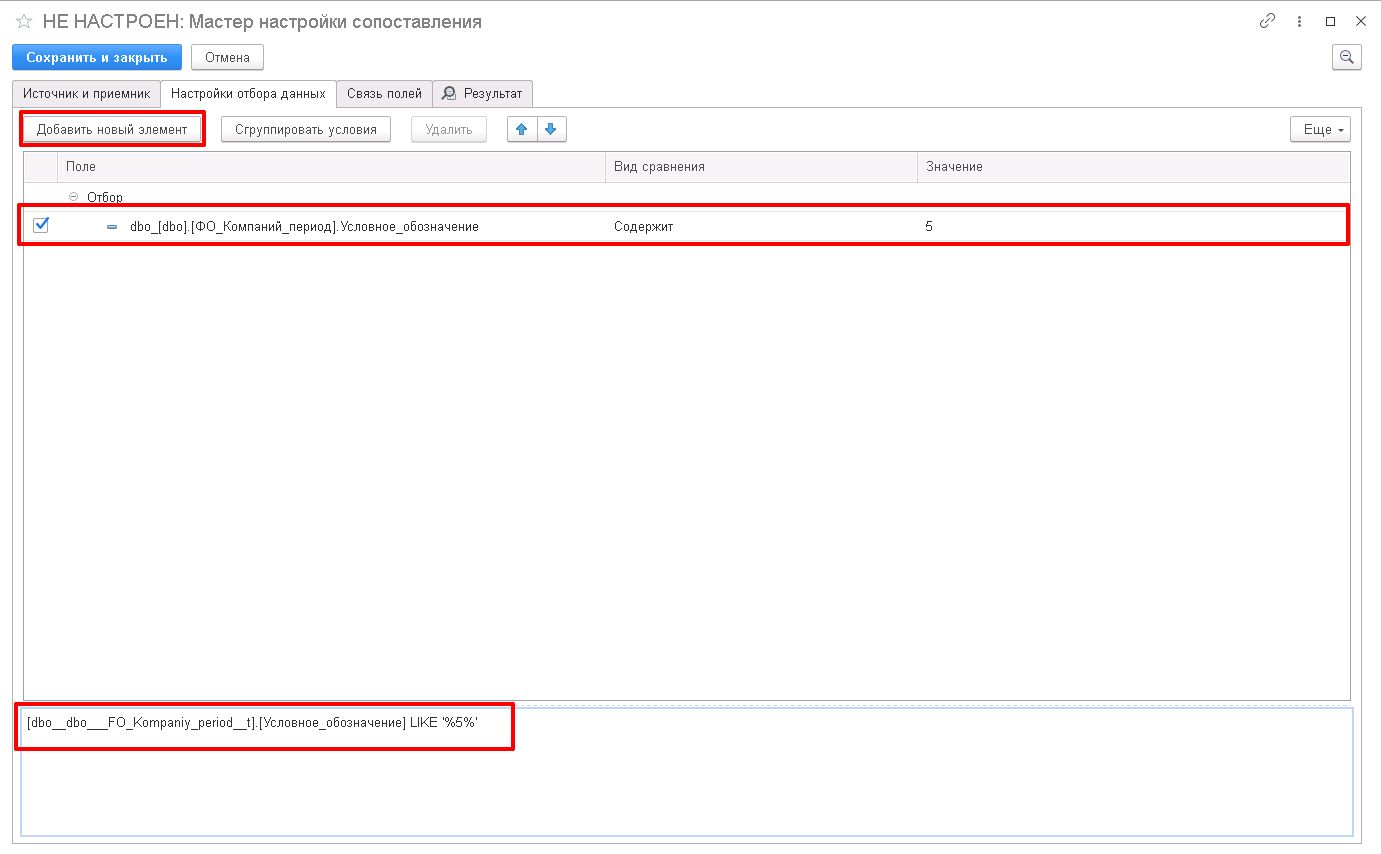
![]()
Для настройки сложных условий фильтрации возможно использовать группировку условий:
- логическое «И» — все условия в группе должны выполняться одновременно;
- логическое «НЕ» — ни одно из условий в группе не должно выполняться;
- логическое «ИЛИ» — достаточно выполнения хотя бы одного условия из группы.
Как настроить группировку:
- Выделите несколько условий.
- Нажмите на кнопку «Сгруппировать условия».
- Выберите нужный логический вариант в заголовке группы.
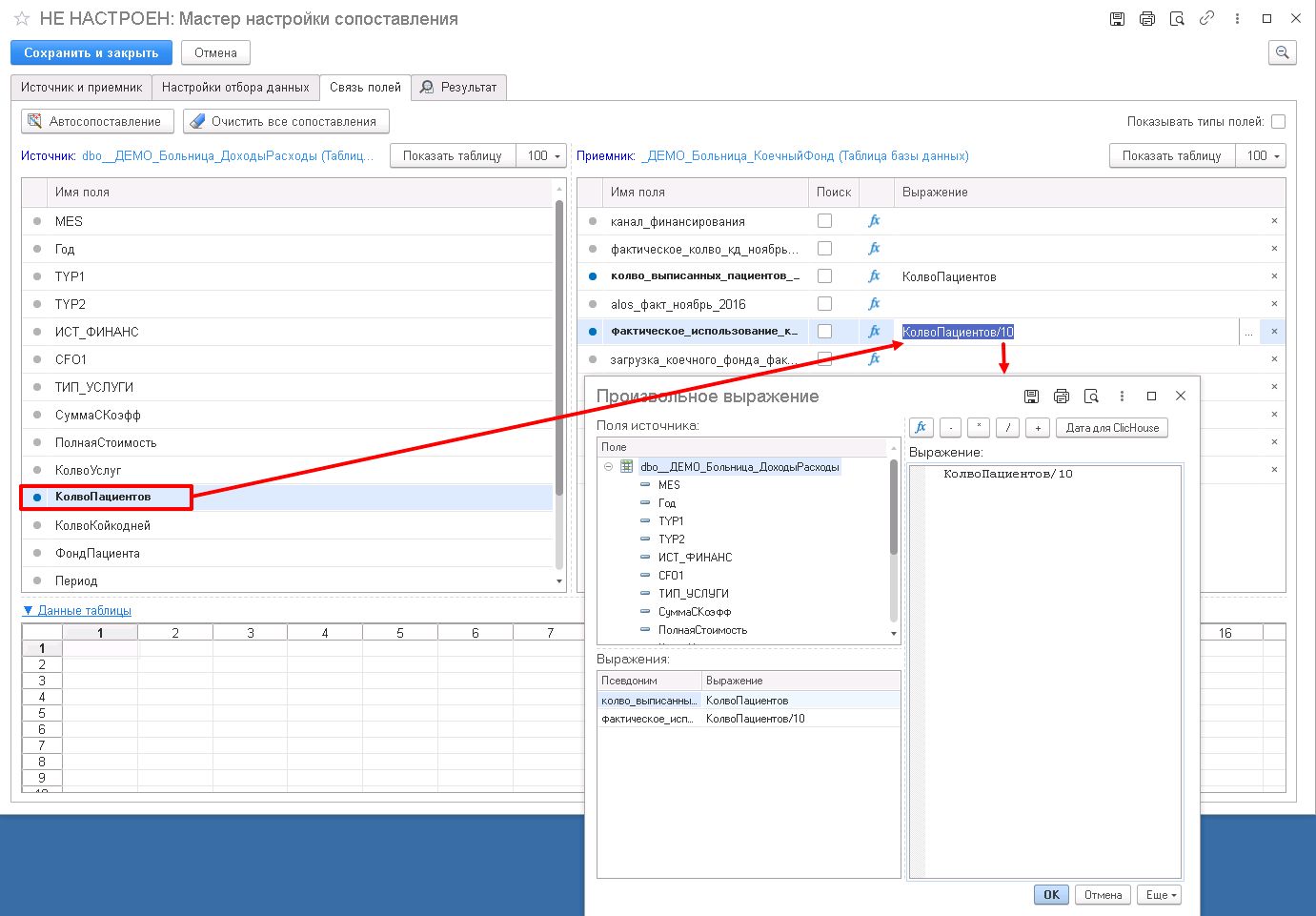
Далее, на вкладке «Связь полей» установите связь полей (рисунок ниже).
![]()
Из левой секции «Источник» (где есть перечень полей таблицы-источника) с помощью мыши методом drag-and-drop переместите нужные поля в правую секцию «Приемник». Если поля называются одинаково, возможно воспользоваться кнопкой «Автосопоставление». Предусмотрена кнопка и быстрой очистки сопоставлений. Над обоими секциями есть кнопки «Показать таблицу» для предварительного просмотра данных.
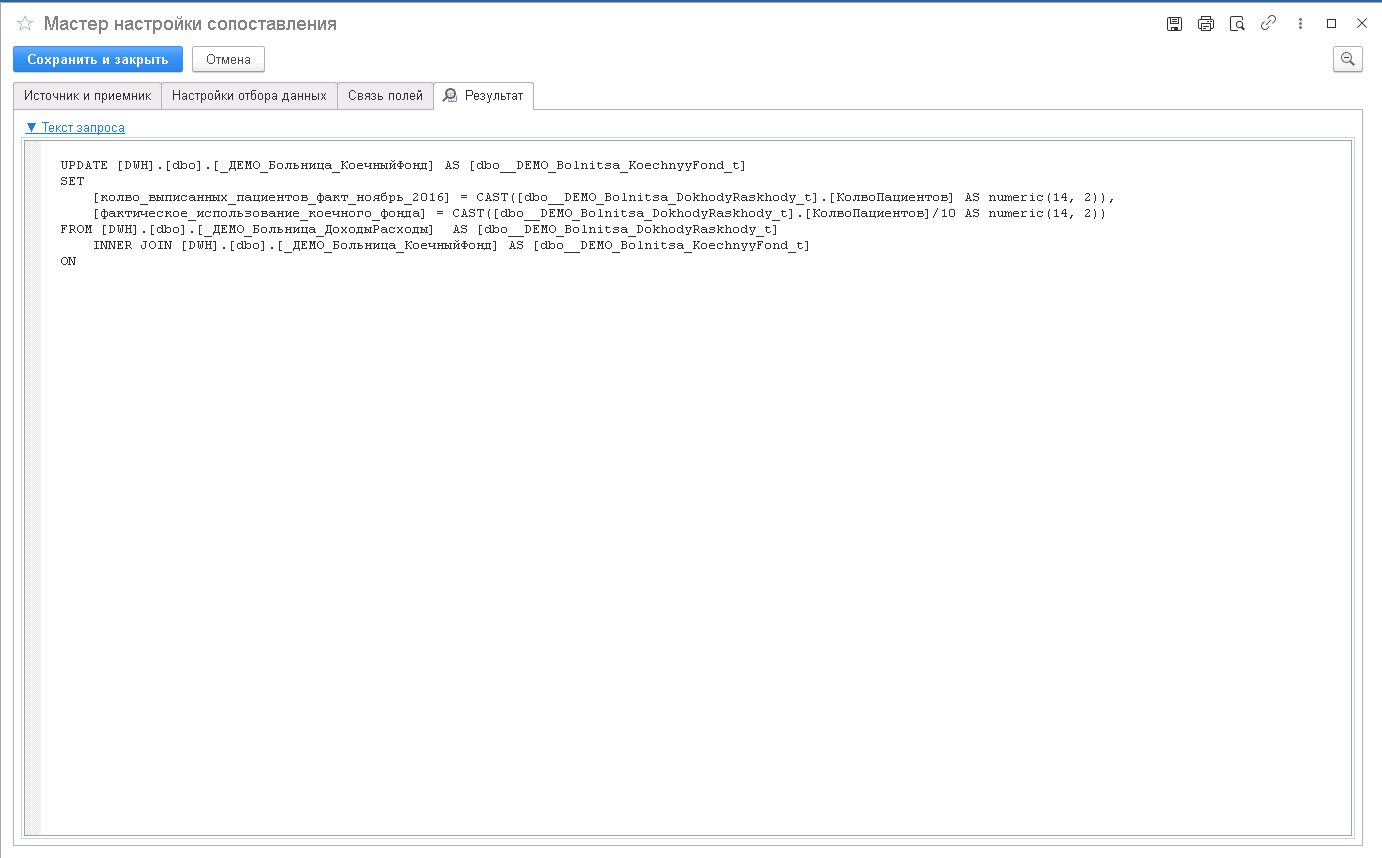
Рассмотрим ситуацию, например, необходимо в приемнике вычислить количество используемых палат, когда в кждой палате находится по 10 пацентов. После двойного щелчка мышью по имени поля в правой секции («фактическое_использование_коечного_фонда») появится кнопка «…», которая вызовет диалоговое окно «Произвольное выражение». В этом окне возможно ввести необходимую формулу для вычислений. В данном случае, необходимо КолвоПациентов разделить на 10. Нажмите на кнопку «Ок».
На вкладке «Результат» вы можете:
- посмотреть, какая таблица получится на выходе;
- проверить текст SQL-запроса, соответствующий текущему шагу.
![]()