



Технические настройки для подготовки к работе - Публичная база знаний Modus
Основные настройки
Для работы системы установите настройки, регулирующие доступ к данным и получение данных. Установленные настройки будут использоваться системой по умолчанию.
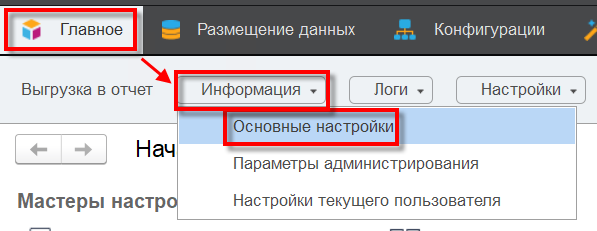
Перейдите в меню: «Главное/ Информация/ Основные настройки».
Настройки получения данных
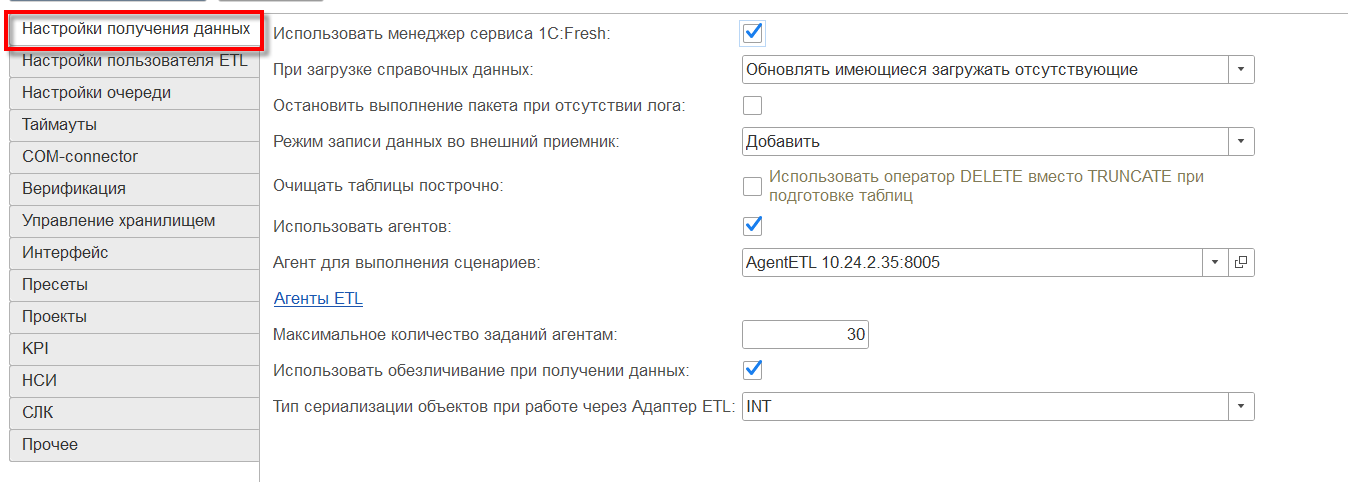
В разделе «Настройки получения данных» устанавливаются правила, по которым обновляются данные.
- «Использовать менеджер сервиса 1С: Fresh» — установите галочку для загрузки справочной информации из менеджера сервиса.
- «При загрузке справочных данных»:
- «Обновлять имеющиеся» — найти имеющиеся данные и, если нашли, обновить их, новые элементы не добавлять;
- «Загружать отсутствующие» — проверить имеются ли данные, если нет — добавить, если есть — ничего не делать;
- «Обновлять имеющиеся и загружать отсутствующие» — комбинация предыдущих пунктов: проверить имеются ли данные, если нет — добавить, если есть — обновить.
- «Режим записи данных во внешний приемник»:
- «Добавить» — дополнить уже имеющийся набор данных (данные могут дублироваться);
- «Очистить и добавить» — удалить имеющиеся данные и загрузить заново;
- «Скопировать и добавить» — сделать копию имеющихся данных (создается новая таблица тем же именем и постфиксом-датой операции), удалить имеющиеся данные и загрузить заново.
- «Использовать агентов» — установите галочку для использования Агентов для сбора данных и/ или выполнения запросов к СУБД.
- «Агент для выполнения сценариев» — Агент, который используется для выполнения запросов к БД;
- «Агенты ETL» — переход к списку всех Агентов;
- «Максимальное количество заданий агентам» — укажите количество заданий по сбору данных из одного источника по одному правилу.
- «Использовать обезличивание при получении данных» — установите галочку для настройки обезличивания в правиле выгрузки.
- «Тип сериализации объектов при работе через Адаптер ETL:»
- «JSON»;
- «JSONORIG»;
- «XML»;
- «INT».
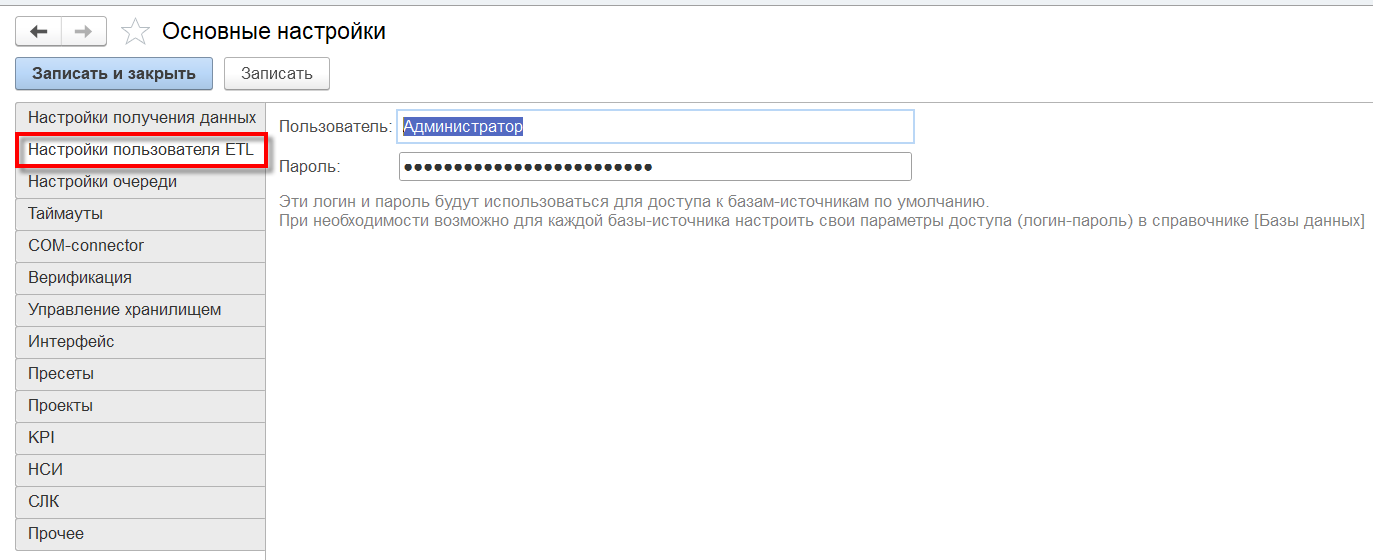
Настройки пользователя ETL
Параметры доступа (логин и пароль) к базам-источникам по умолчанию. При необходимости возможно для каждой базы-источника настроить свои параметры доступа в справочнике «Базы данных»:
Настройки очереди
Настройки, предназначенные для оптимизации процесса загрузки и выгрузки данных:
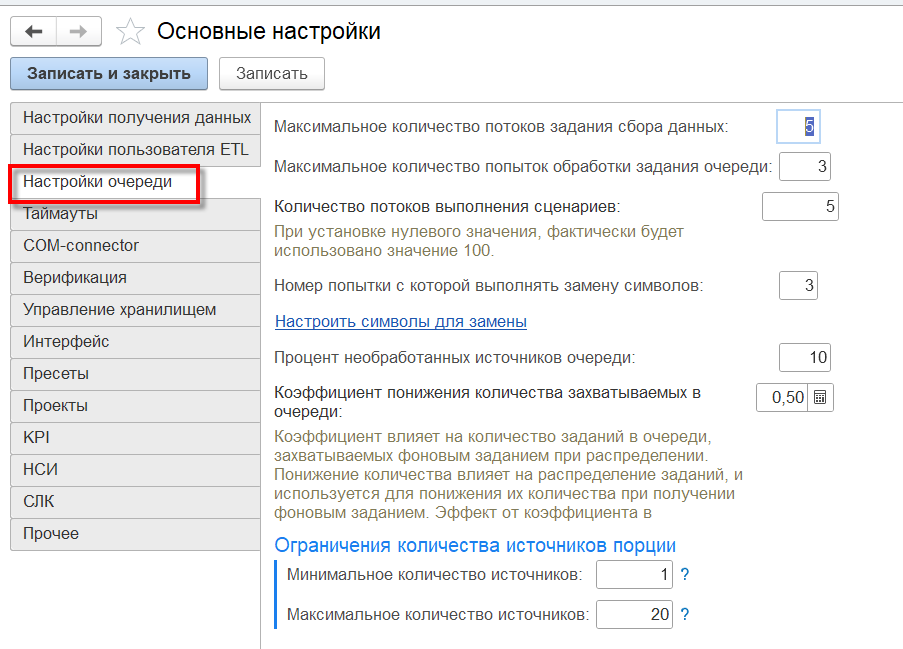
- «Максимальное количество потоков задания сбора данных» — количество параллельно запускаемых фоновых заданий при работе регламентного задания сбора данных. При увеличении количества потоков увеличивается скорость получения данных, но когда потоков слишком много они начинают мешать друг другу и вместо увеличения скорости происходит задержка;
- «Максимальное количество попыток обработки задания очереди» — позволяет пытаться выполнить задание несколько раз, это нужно из-за того, что подключение к источнику данных может быть нестабильно и однократное обращение может привести к ошибке;
- «Количество потоков выполнения сценариев» — параметр позволяет установить максимальное количество параллельных потоков выполнения сценариев, которые система может использовать для обработки;
- «Номер попытки, с которой выполнять замену символов» — бывают ситуации, когда не удается записать полученные данные, так как они содержат спецсимволы. В системе настроена замена некоторых символов («’», «-», «>», «`», …), можно их искать и заменять в первой же, но тогда идет увеличение времени получения данных, поэтому устанавливаем номер попытки — т.е. если в первых попытках записать не получилось, то пробовать сделать замену символов;
- «Настроить символы для замены» — замена символов в строках получаемых данных;
- «Процент необработанных источников очереди» — это количество допустимых ошибок в очереди. Например, получаем данные из 100 источников, считаем, что если из 90 или более источников данные получены, то получение прошло успешно. Тогда устанавливаем процент — 10.
- «Коэффициент понижения количества захватываемых в очереди» — влияет на количество заданий в очереди, захватываемых фоновым заданием при распределении.
- «Ограничения количества источников порции» — минимальное и максимальное количество источников, которое фоновое задание может взять в обработку:
- «Минимальное количество источников»;
- «Максимальное количество источников».
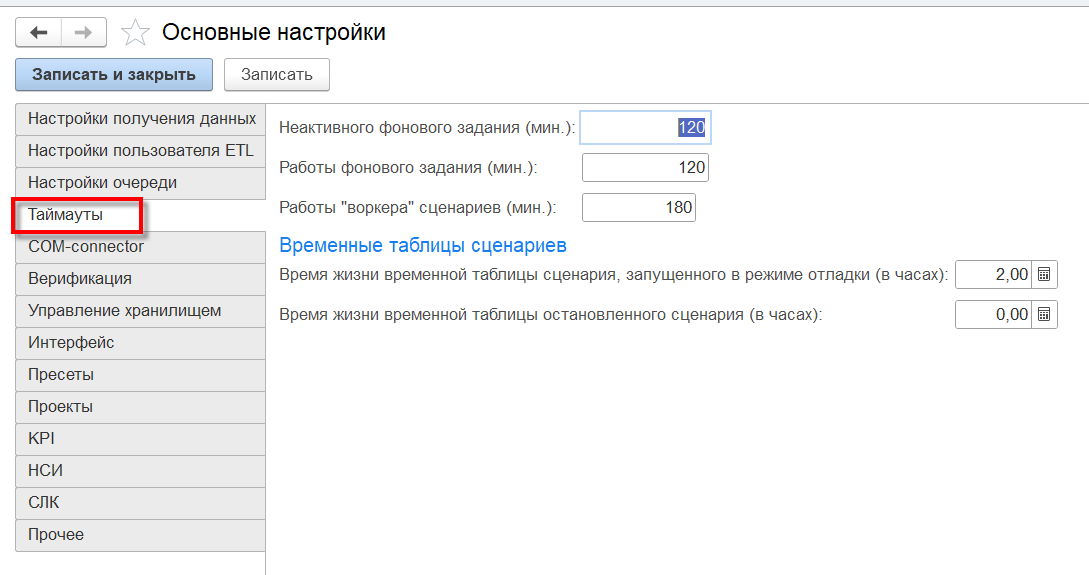
Таймауты
Настройки времени ожидания при выполнении фонового задания:
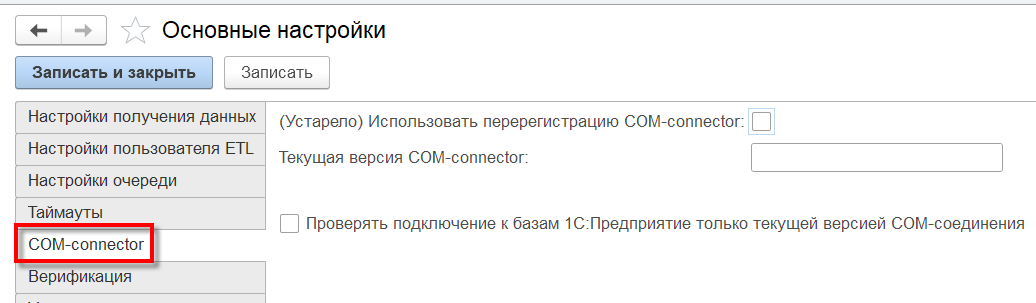
COM-connector
Настройки COM-connector:
Верификация
«Использовать верификацию данных» — установите галочку для включения механизмов проверки данных на соответствие стандарту, на соответствие эталонным значениям.
Управление хранилищем
- «БД SQL по умолчанию» — база данных — хранилище по умолчанию;
- «Использовать управление хранилищем» — при включении опции в верхнем меню отобразится раздел «Управление хранилищем», подробнее см. раздел «Общие настройки Мастера интеграции»;

- «Использовать трансформацию таблиц в схему Звезда» — включает подсистему трансформации таблиц в схему звезда, подробнее см. раздел «Трансформация в схему «Звезда»».
Интерфейс

- «Количество отображаемых пакетов виджетом контроля» — количество отображаемых пакетов виджетом контроля на начальной странице;
- «Количество отображаемых прогрессов очередей виджета очередей» — количество отображаемых прогрессов очередей виджета очередей на начальной странице;
- «Выбирать только "Пользовательские типы" в полях выбора типов» — ограничивает выбор типа поля только пользовательским типом;
- «Упрощенный ввод квалификаторов типов» — упрощенный режим ввода квалификаторов типа.
Пресеты
«Использовать пресеты» — включает подсистему «Пресеты», используемую для выгрузки и загрузки настроек, подробнее о работе см. раздел «Пресеты».
Проекты
«Использовать проекты» — включает возможность указания проектов, подробнее см. раздел «Разграничение доступа в разрезе проектов».
KPI
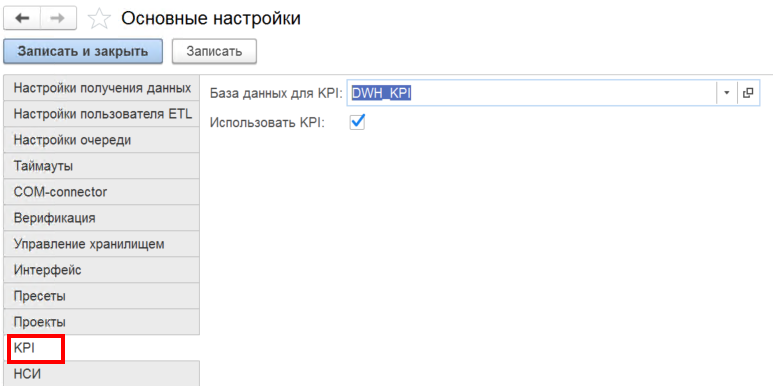
- «База данных для KPI» — база данных, в которой будут сформированы таблицы KPI;
- «Использовать KPI» — создание и выполнение сценария формирования таблиц KPI в указанной базе данных.
НСИ
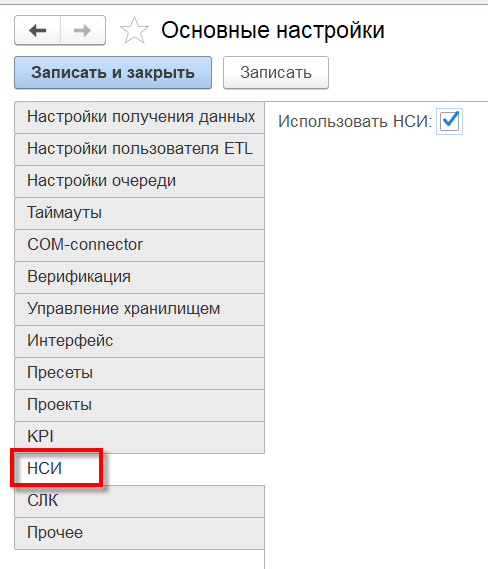
«Использовать НСИ» — включает модуль учета нормативно-справочной информации, предназначенный для хранения и использования объектов НСИ — справочников и маппингов (маппинг — соответствие / связь элементов первичных данных элементам справочников). Подробнее о НСИ смотрите в разделе «Модуль НСИ».
СЛК
Настройки системы лицензирования и защиты конфигурации:
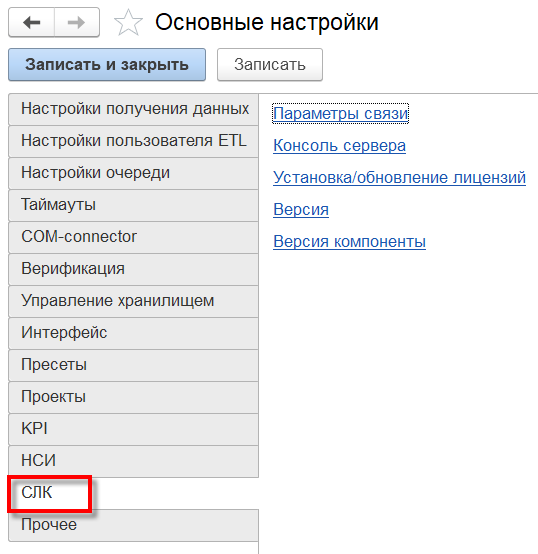
- «Параметры связи» – настройка параметров связи с сервером СЛК;
- «Консоль сервера» – консоль сервера лицензирования выводит текущие параметры СЛК и служит для диагностики проблем;
- «Установка/обновление лицензий» – интерфейс для запуска процедур по установке и активации лицензий. Подробнее о работе СЛК см. раздел «Установка СЛК» и «Мастер первичной настройки»;
- «Версия» — нажмите чтобы знать версию СЛК;
- «Версия компонентов» — нажмите чтобы узнать версию компонентов СЛК.
Прочее
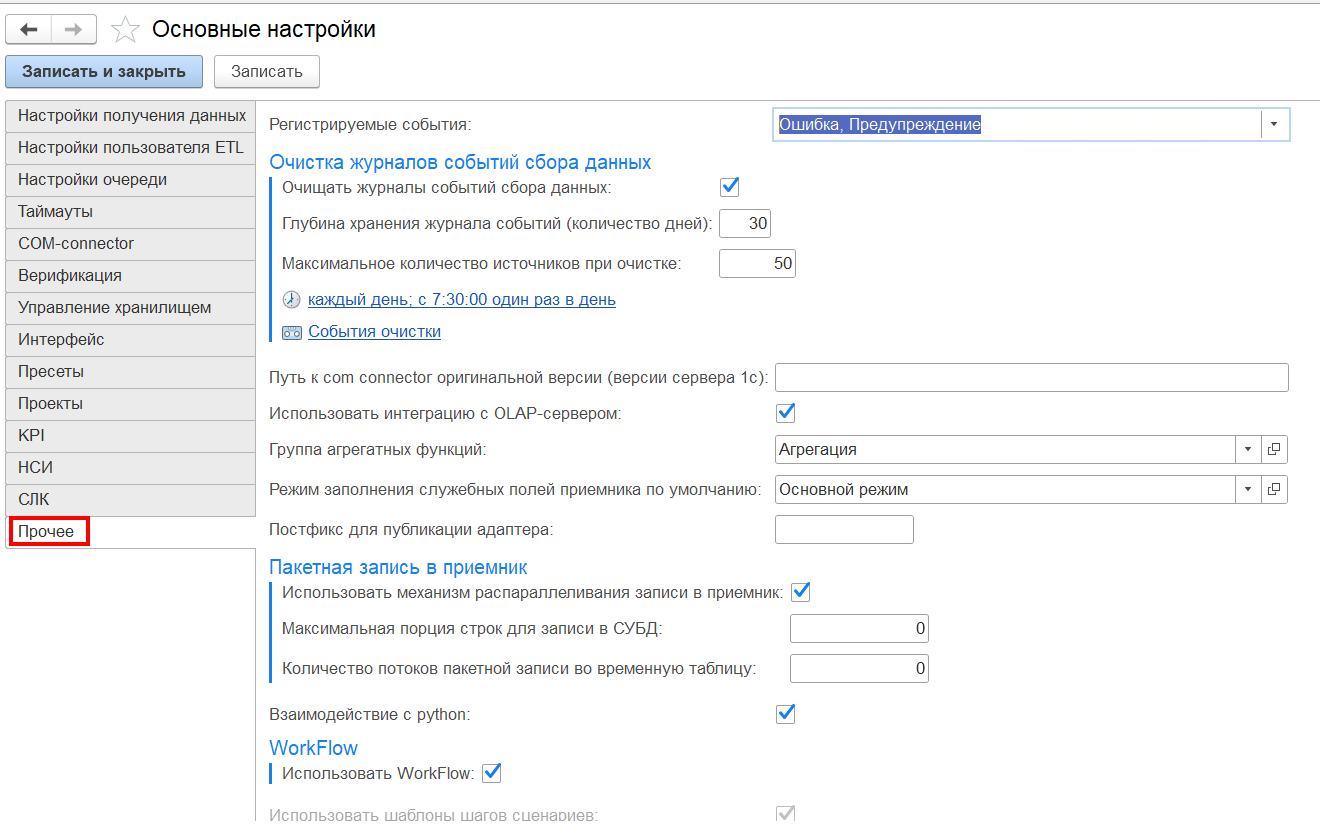
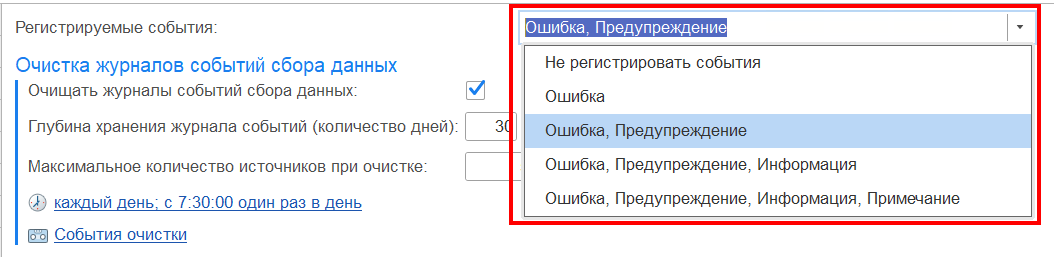
- «Регистрируемые события» — позволяют настроить уровень детализации события:
- Не регистрировать события;
- Ошибка;
- Ошибка, Предупреждение;
- Ошибка, Предупреждение, Информация;
- Ошибка, Предупреждение, Информация, Примечание.
Подробнее о событиях, которые фиксируются в фактах выгрузки, см. раздел «Логирование выгрузки данных».
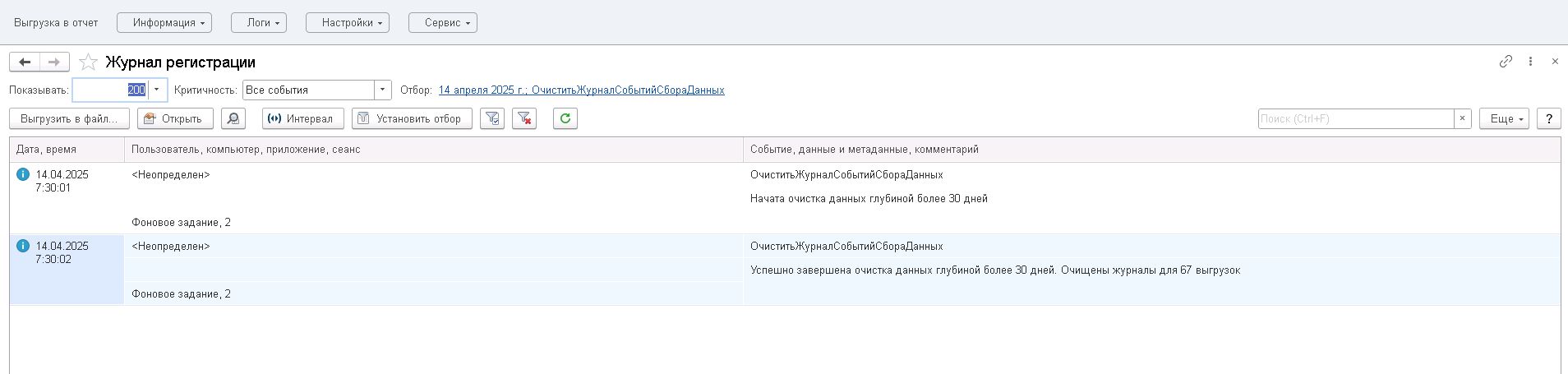
Группа настроек «Очистка журналов событий сбора данных», представлена:
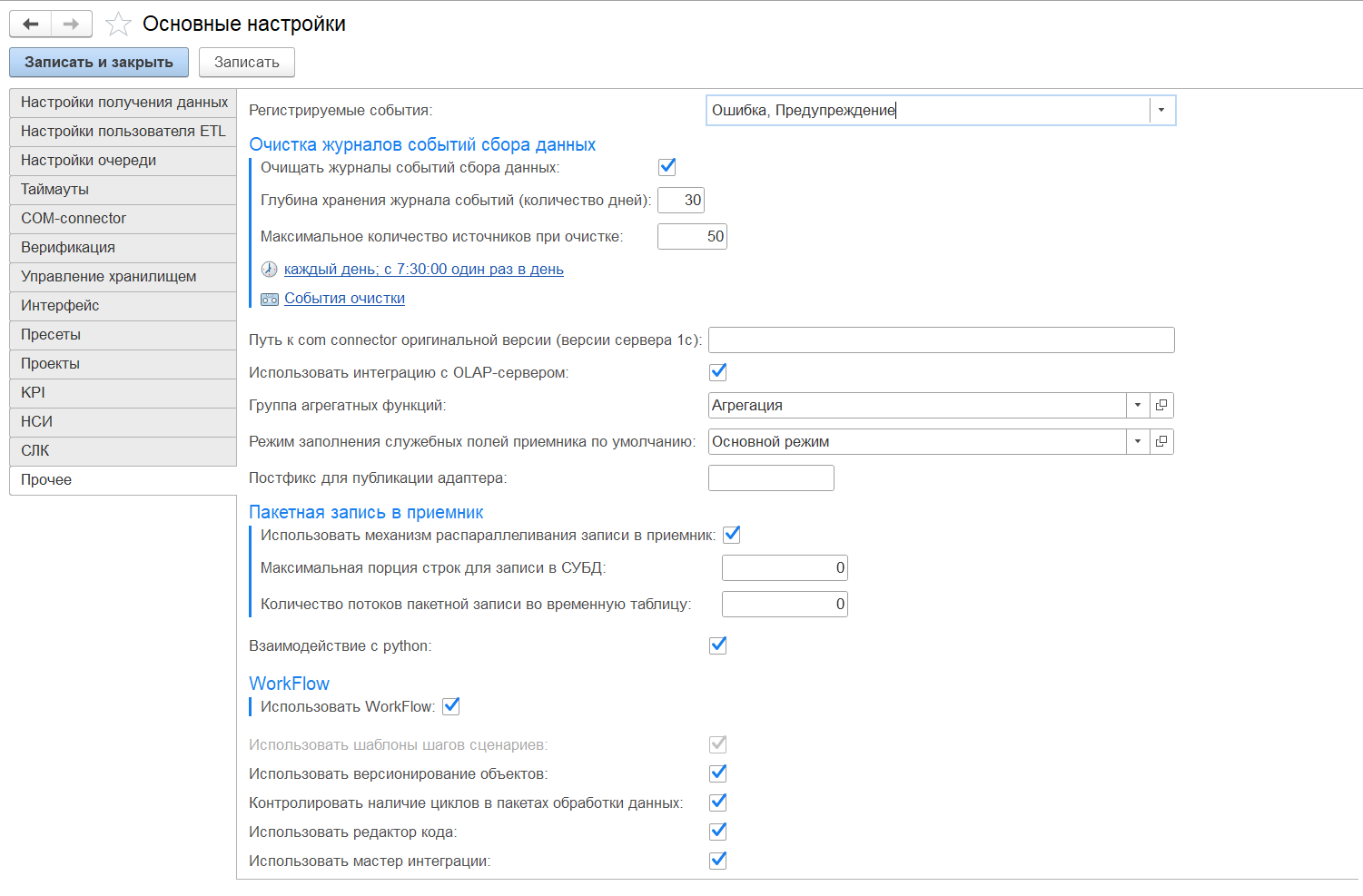
- «Очищать журналы событий» — при установке галочки будет происходить очистка журнала событий по установленным настройкам;
- «Глубина хранения журнала событий (количество дней)» — количество дней, по прошествии которых будут автоматически очищены записи в журналах, относящиеся к фактам выгрузки, сценариям обработки данных. Периодическая очистка позволяет оптимизировать объем, занятый логами, и способствует быстрой работе отчетов по логам;
- «Максимальное количество источников при очистке» — максимальное количество источников, по которым будут очищены записи в журнале событий сбора данных;
Примечание — расписание устанавливается для очистки журнала регистрации относительно событий, которые нужно удалить. Поэтому обратите внимание на то, что было выбрано в поле «Регистрируемые события».
- Настройка расписания — нажмите на строку ссылку
 в диалоговом окне «Расписание», настройте:
в диалоговом окне «Расписание», настройте:
-
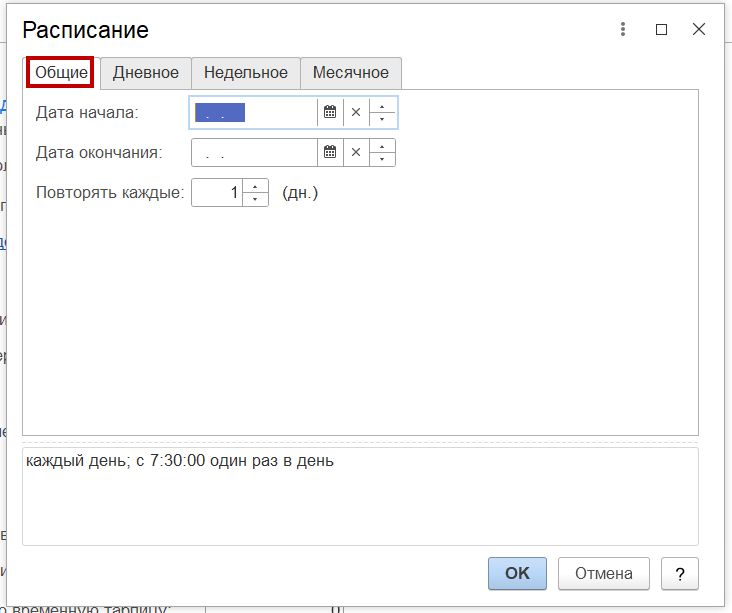
На вкладке «Общее» — указываются дата начала и завершения задания и режим повтора.
-
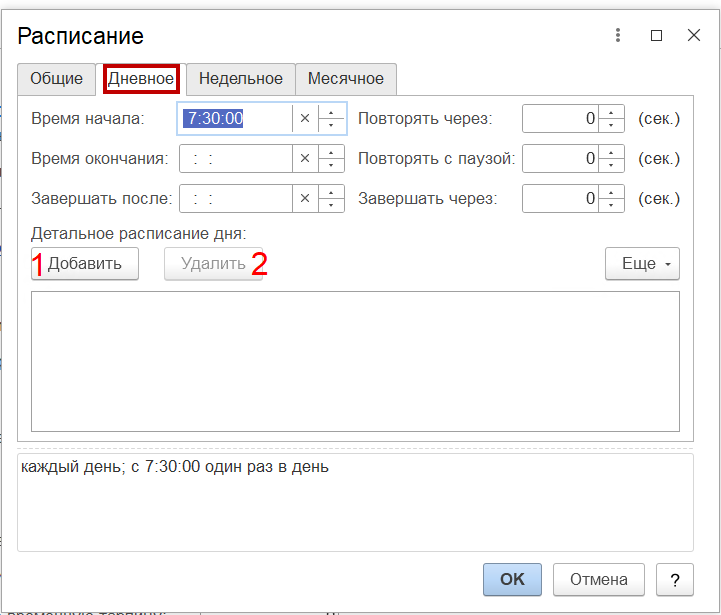
На вкладке «Дневное» — указывается дневное расписание задания. Укажите в формате «ЧЧ:ММ:СС» значения в полях «Время начала», «Время окончания», «Завершать после», в секундах установите значение в полях «Повторить через», «Повторять с паузой», «Завершать через». При необходимости настройки детального расписания установите необходимые значения и нажмите на кнопку «Добавить» (1), аналогично добавьте необходимое количество значений. При необходимости настройки добавленного значения выберите его в таблице и измените значения в полях. Для удаления значения выберите его в таблице и нажмите на кнопку «Удалить» (2)
;
- На вкладке «Недельное» — указывается недельное расписание задания. Установите на данной вкладке галочку в необходимых полях дни недели и при необходимости укажите значение периода повтора в неделях в поле «Повторять каждые»;
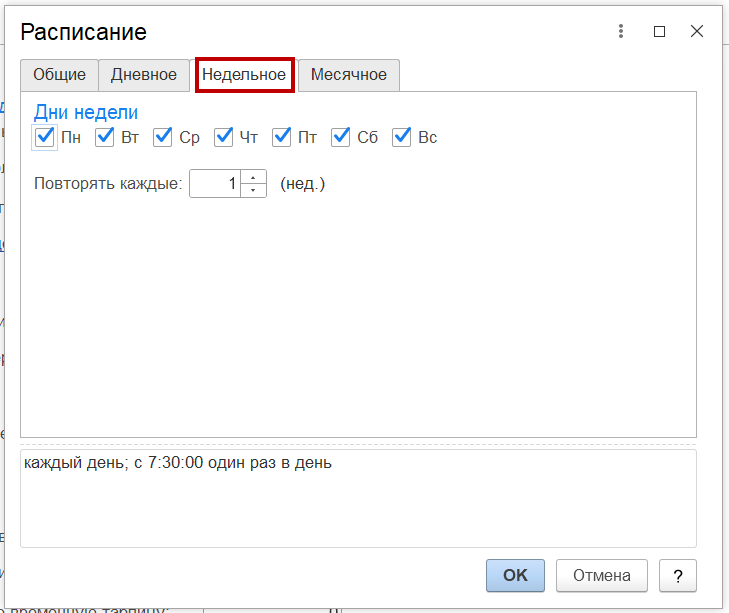
- На вкладке «Месячное» — указывается месячное расписание задания. Установите на данной вкладке галочку в необходимых полях месяца, а также при необходимости настройте поля «Выполнять в ... день месяца с начала/ с конца» и «Выполнять в ... день недели в месяце с начала/ с конца».
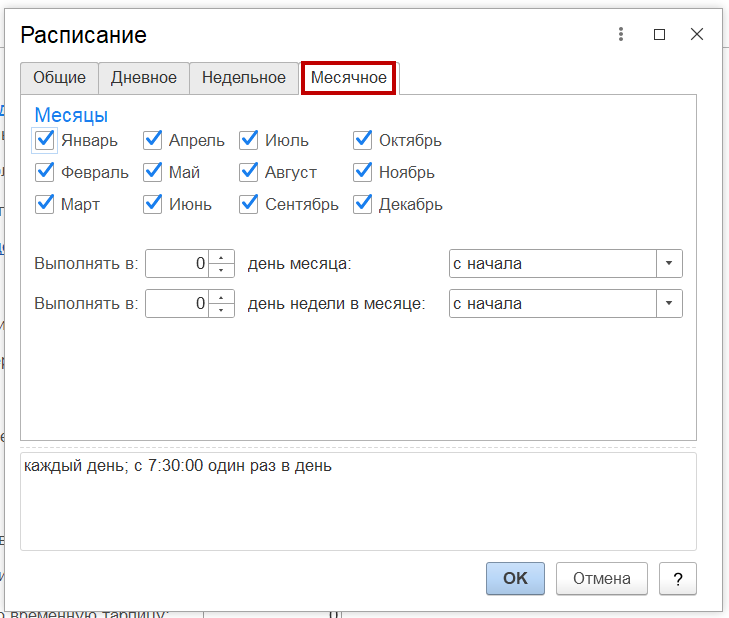
-
- «События очистки» — при нажатии на ссылку отобразится окно «Журнал регистрации»;
«Путь к com connector оригинальной версии (версии сервера 1С)» — имя компьютера, на котором будет создан com объект.
«Использовать интеграцию с OLAP-сервером» — для включения возможности интеграции с «Полиматикой».
«Группа агрегатных функций» — агрегатные функции, доступные для выбора в мастере группировки данных.
«Режим заполнения служебных полей приемника по умолчанию» — режим заполнения служебных полей в правиле выгрузки по умолчанию.
«Постфикс для публикации адаптера» — постфикс базы данных источника.
Группа настроек «Пакетная запись в приемник», представлена:
- «Использовать механизм распараллеливания записи в приемник» — признак доступности пакетной записи для базы данных;
- «Максимальная порция строк для записи в СУБД» — параметр устанавливает максимальное количество строк, накапливаемых в буфере перед выполнением массовой операции вставки (batch insert) в базу данных;
- «Количество потоков пакетной записи во временную таблицу» — параметр, определяющий число параллельных потоков (threads), используемых для одновременной массовой вставки данных во временную таблицу.

«Взаимодействие с python» — для использования функционала машинного обучения, если флаг установлен, в сценариях доступны мастера «Кластеризация», «Регрессия. Обучение», «Регрессия. Предсказание», «Классификация.Обучение» и «Классификация.Предсказание».
Группа настроек «WorkFlow», представлена:
- «Использовать WorkFlow» — визуальный интерфейс проектирования сценариев обработки данных.

«Использовать шаблоны шагов сценариев» — шаблоны позволяют формировать скрипт трансформации данных для шага сценария, используя визуальный интерфейс.
«Использовать версионирование объектов» — параметр, позволяет определить, сохранять ли историю изменений объектов (записей) в базе данных вместо прямого обновления или удаления данных. Подробнее см. раздел «Версионирование объектов в Modus ETL».
«Контролировать наличие циклов в пакетах обработки данных» — позволяет контролировать наличие циклов пакетов обработки данных предназначенных для автоматического запуска заданий по обновлению данных. Подробнее см. раздел «Пакеты обработки данных».
«Использовать редактор кода» — позволяет использовать консоль запросов, для проверки выполнения кода в интерфейсе ETL, подробнее см. «Консоль запросов».
«Использовать мастер интеграции» — включает модуль «Мастер интеграции», который позволяет подключать платформу к внешним источникам данных, таким как CRM-системы и другие базы данных, подробнее см. раздел «Мастер интеграции».
Параметры администрирования
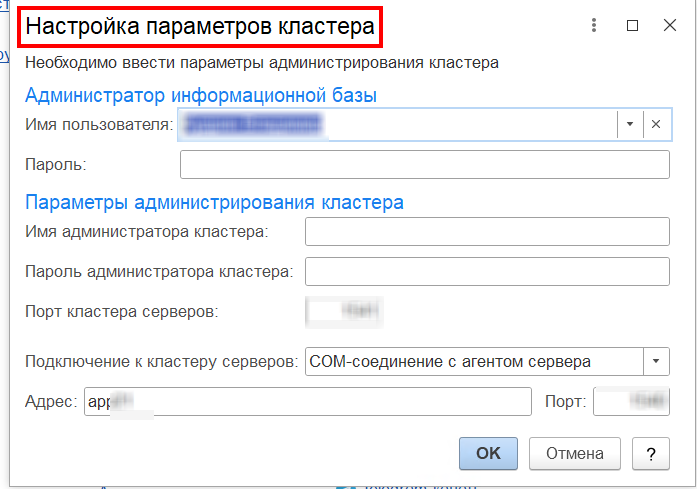
Для выполнения различных административных действий на кластере серверов 1С, необходимо установить параметры администрирования кластера. Расположение в меню: «Главное/ Информация/ Параметры администрирования»:
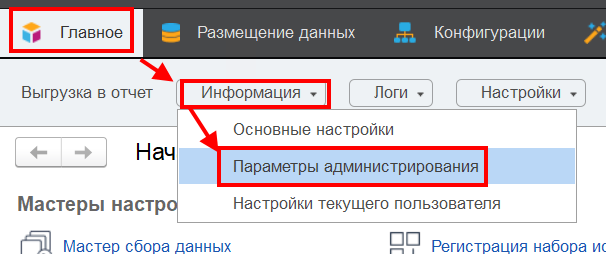
В открывшемся диалоговом окне заполните требуемые поля:
- логин и пароль администратора информационной базы;
- логин и пароль администратора кластера;
- «Порт кластера серверов» (менеджер кластера);
- «Подключения к кластеру серверов» (выберите из выпадающего вариант);
- «Адрес» (адрес сервера 1С);
- «Порт» (порт агента сервер).